Skyplane 浅述
这几天在看算力网络相关的东西,老师让调研一下 Skyplane,于是花时间看了一下。
UPD:说实话之前我不是很看好这个研究,感觉好里面有点一般,一般里有点好,但是他们中 NSDI 2023 了,所以不得不看了。
文章中图片,表格和数据全部来源于论文。
个人评论仍用引用表达,并且可能有失偏颇,请勿引用。
注:本文将 bulk 翻译为「大文件」,不太清楚是不是专用术语。因为 bulk 本身的意思就强调它大,但是它同时是一个块文件而不是一个文件流,所以先就这样吧,希望不要有歧义。region 翻译为「地域」,虽然直接叫 region 也行,就是这个集群的地理位置,同样也希望不要有歧义。
Abstract
现如今的云应用正把数据越来越广泛地分布在多个地区和云服务提供商上。但是,跨区域大文件传输通常是很慢的,并限制了应用程序的性能。我们论证了可以在现有网络上应用一种新的覆盖网,使得区域之间传输大文件的吞吐量提高——具体是通过应用层上通过非直接路径路由数据来实现的。然而,直接在目前的云上应用这种覆盖网会导致不可接受的出云费用增加。我们设计了 Skyplane,这是一个在云对象存储之间进行大量数据传输的系统,它使用云感知覆盖网来优化价格和性能之间的权衡。Skyplane 的规划器使用混合整数规划来确定数据传输的最佳叠加路径和资源分配,并且满足用户提供的价格或性能约束。Skyplane 在一个云上的传输性能比公共云传输服务高出 4.6 倍,在不同云间的传输性能高出 5.0 倍。
这里的「在一个云上的传输性能比公共云传输服务高出 4.6 倍」应该指的是在同一个云服务的不同地域之间拷贝。比如 AWS 的美东到孟买什么的。不同云就是跨云的,比如 AWS 到 Azure 的传输等等。一般跨云都会跨地域,所以就没有再强调地域不同。
Intro
一份对 727 位受访者的调查显示,超过 86% 的受访者采用了多云(multi-cloud)的策略。主要是由于隐私合规,使用一些定制的硬件,或者避免供应商锁定。
隐私合规是一个非常重要的问题,我认为在这里是主要问题。这里的隐私合规是指数据存储必须在本地(物理的地域),并且限制数据外传处理的场景。使用定制硬件也是一个问题,比如某个区域可能没有 GPU 或者 FPGA 的服务器,但是训练模型的话需要先过一遍 FPGA 再过一遍 GPU,这时候就需要大规模迁移数据。供应商锁定指对某个供应商形成了强依赖,要切换的话就要花费巨大的代价的情况,可以看这篇博客了解。
应用在数据中心之间传输数据为了批处理(比如 ETL,基于地理的统计)和提供产品服务(比如搜索指数)。
除了那个基于地理统计之外其他的例子引用的论文里基本都不是围绕它做的,ETL 引的一个 CIDR 论文,主要做数据湖的,搜索指数那个引的是 SD-WAN 的论文,意义不明。
在应用定义的最低性能约束下,广泛的前期工作优化了数据中心之间批量数据传输的吞吐量。所有主要的云服务提供商都提供了大文件的传输服务,比如 AWS DataSync,Azure AzCopy 和 GCP Storage Transfer Service。
从云服务用户的视角,传输的吞吐量和花费(价格)是云上传输的两个非常重要的量度。因此出现了一个主要问题,就是我们如何针对云上大文件传输优化花费和吞吐量。
一个自然的方法就是优化云服务商外部网络的路由协议,以支持高吞吐数据传输。但这不可行,有以下两个原因:首先针对大文件高吞吐传输而重构 IP 层路由协议可能对网络延迟敏感的程序产生负面影响。
因为延迟和吞吐量是互相制约的。高吞吐一般带来高延迟,低延迟网络吞吐量一般不高。
其次云服务提供商没有动力优化从自己家向其他云迁出的数据传输。
存储是要卖钱的,大家都希望入流量大但是出流量小,所以经济利益也不会让云服务商去优化出流量的传输。我觉得这是主要原因,因为想优化的话,在第一点其实技术上是可行的,多开一个集群负责大文件的传输,或者把延迟敏感和吞吐量需要大的应用做网络切片隔离开,从技术上都是可以做到的,但毕竟不赚钱,所以没有这样的服务。
事实上,AWS DataSync,AzCopy,GCP Storage Transfer,AWS Snowball 和 Azure Data Box Disk 都支持迁入数据到自己的云而不支持从自己的云迁出数据。跨云对等传输优化必须在起点和终点的云服务上都进行。
一个关键的观察是我们可以确定一条地域之间的覆盖网路径,沿这条路径传输比直接传输更快。比如 Azure 的 Central Canada 集群和 GCP 的 asia-northeast1 之间的直接路径吞吐量是 6.2Gbps。Skyplane 可以在 Azure 的 US West 2 集群做中转,达到 12.4Gbps 的吞吐量,这是直接传输的 2 倍。最重要的是,这可以在云服务商网络之上实现,而不需要他们去实现什么。
文章里写的是 without their explicit buy-in,这个 buy-in 是个特殊用法,但是现在一看就头疼,之前写的业务有个叫百应的,它英文就是 BuyIn。
Skyplane 不是第一个在公共 Internet 上使用覆盖网的(RON 应该是第一个),但是已有技术忽略了公有云的两个关键问题:价格和弹性。
首先,最高带宽的覆盖网路径可能有着无法接受的高价格。云服务提供商对覆盖网路径上每一跳的数据出口分别收费。为了减少花费,在性能和开销之间权衡就十分必要。比如在一个传输方案中,使用 Azure 的 East Japan 集群做中转可以达到 13.9Gbps 的吞吐量,但是开销要比直接传输高 1.9 倍。相反地,使用 Azure 的 West US 2 集群只有 1.2 倍的开销,但是性能近似。因此,Skyplane 在一个比传统的应用级路由更丰富的问题空间中运行——在这里,云实例和云出口的费用是很重要的。
之前的研究仅考虑了带宽的影响,那这就很简单,仅需考虑一个最大流就行了,但是现在问题变成了费用流问题。
其次,RON 网络中考虑的两节点之间的带宽是固定的,但在 Skyplane 的设定上,带宽取决于弹性——在每个云地域上分配更多资源的能力。例如,可以通过简单地在每个地域增加 VM 实例来增加覆盖网路径的容量。每个云地域的物理机数量是有限的,云服务提供商以实例限制的形式将其转给用户,但是覆盖网可以使吞吐量提高到超过这个限制。因此 Skyplane 在一个比传统的应用级路由更丰富的解空间中运行——在这个空间中,由于云的弹性,我们必须选择作为中继的 VM 数量。
这里也体现了我们现在的问题不仅是一个费用流问题,而是每个节点都可以被拆成 VM 数量个点。现在不一定只能起一个 VM,而是可以起多个一起并行传输。因为按量收费实际上在 VM 启动的开销上不大,主要是网络费用,剩下的 CPU 费用实际上十分便宜,而且理论上在网络传输中 I/O 占主导,并不会大量进行 CPU 密集型操作,起多个 VM 占带宽是比较合算的。
而且 AWS 和 GCP 这些好像都是有免费 VM 额度的,没用过不知道了。
Skyplane 同时解决了价格和弹性问题,使用户能够在利用云资源的弹性的同时在价格和性能之间进行权衡。实际上 Skyplane 的核心是一个规划问题,用户的限制就是这个规划问题的限制,我们可以把这个问题规约到一个混合整数规划问题,然后松弛到一个整数规划问题求解。
混合整数规划问题就是一些
必须是整数,但是另一些可以不是的线性规划问题,实际上就一个更 general 的费用流问题,但是费用流问题也是一个线性规划问题,所以这么说倒也没啥问题。
Background
覆盖网
值得提到的覆盖网有 Chord,RON,Bullet,Baidu BDS 和 Akamai 的骨干网。
他要不说百度的 BDS 我还真不知道这个事情……
虽然 ISP 对他们管辖的网络有全局视野,但 ISP 选择路由的量度可能不与用户偏好对齐。今天的 WAN 不允许用户添加其他的路由偏好,而覆盖网给应用提供了一个机制来控制路由。比如 Akamai 使用覆盖网降低 CDN miss 的延迟,RON 通过一个未受影响的中间主机绕过网络中断的路线。
RON 是通过嵌入在一组固定的路由器中的探测器,定期测量网络性能来实现的。当发生路径中断时,RON 选择一个中继路由器来规避中断。这个中间路由器选择为客户端和服务器之间具有较低的数据包丢失或延迟的一个。另外,RON 可以使用 TCP Reno 的吞吐量模型来选择中间路由器。RON 一般只选择一个中间节点。
云上的 WAN
从云客户的角度来看,云是有弹性的。比如资源不够用了可以扩容。但是再扩也扩不出超过物理实际有的资源。所以云服务提供商对其客户的资源(如虚拟机)施加服务限制。
每个 VM 的带宽被实例类型限制。比如 AWS 的 m5.8xlarge 实例可以用最多 10Gbps 带宽,Azure 的 Standard_D32_v5 实例最多可以用 16Gbps 带宽。此外,只有部分带宽可用于向另一个云提供商的出口流量。
这种情况国内没见过,我感觉我们租服务器的时候大概最多 300Mbps,可能这只是华为云一家的情况吧。而且也没见过只有部分带宽能向其他云提供的情况,比如阿里云向华为云最多只能用 100Mbps 这种。
云服务商不同,限制策略也不同。值得注意的是 Azure 是没有限制的。当然,实际能达到的 TCP 网络带宽还要考虑拥塞控制,所以可能比限制的数值要低。
云服务出口计费
注:这里的出口计费,出流量计费原文表述均为 egress pricing,说实话同样也不知道有没有术语描述,希望没有歧义×3。
云服务提供商向出流量收费。重要的是,出口计费基于传输数据的大小,而不是传输速率。
这里对速率的表述是 rate,有点怪怪的。
以 10Mbps 或者以 10Gbps 传输同一个文件,出流量计费是相同的。出流量计费产生了计费上的不对称——入流量是不收费的。
国内对于按量计费的说法十分模糊,在购买的时候只会提「流量」这个概念,而不会细分入还是出。要想查是入还是出还要翻一堆文档,腾讯云的文档在这里,表示是出流量付费,那这就是统一的了。
对于云内数据传输(即在同一个云的不同地域之间传数据),在地理位置远的两个地域之间传数据要比近的之间贵。相反地,对于跨云传输(即在两个不同的云服务商之间传数据),无论地理距离有多少,在相同传输速率下花费相同。比如,从单个 Azure 地域传出数据到 Azure 外的出口费用都是相同的,包括 AWS 和 GCP 的任何可用区。
还有这事?
云上对象存储
现在各种云都提供对象存储服务,简单来说就是像一个 KV 数据库一样,向这个服务提供 Key,返回给用户一个文件。但是这种存储是不可变的,如果要改一个版本,就要存新版本进去,而不是修改它。然后用分布式一致性模型同步这些对象。大对象通过分片可以支持并发写。对一个分片的读吞吐量可能被云服务商限制(Azure 限制为 60MB/s)。
Overview of Skyplane
为了使用 Skyplane,用户首先安装 Skyplane 客户端,然后配置云服务商提供的 secret key 使其能访问用户的云服务。然后用户提交一个任务和价格、带宽的限制。限制可以有如下两种形式:可以要求 Skyplane 在一个价格上限优化带宽,或者在一个带宽下线优化价格。
Skyplane 本身包含了一个规划器和一个数据面。
这个规划器其实就是控制面。
Skyplane 和传统覆盖网的关键不同时 Skyplane 把费用纳入了规划传输路径的考虑范围之中。具体地说,Skyplane 的规划器使用价格矩阵和吞吐量矩阵来确定使用哪条路径。价格矩阵确定了在每对云区域之间(双向)传输数据的价格。我们基于云服务商网站和云 API 查询的信息来计算这个矩阵。吞吐量矩阵是直接测量得到的。
注意吞吐量矩阵的测量是使用 TCP 连接的,这是在 TCP 拥塞控制之下测量的。因此,吞吐量矩阵内的数据是单个用户传输数据的可用带宽,并考虑到其他用户流量的交叉流量。我们假设 WAN 上的流量统计复用程度很高,换句话说,与可用的区域间总带宽相比,单个用户的批量传输所消耗的带宽可以忽略不计。
太学术了,看半天没看懂,扔翻译里就看懂了。
这就允许 Skyplane 用户不需要考虑其他用户的数据传输而安排传输计划,使用吞吐量矩阵就好。
这一段就是在解释吞吐量矩阵是可以复用的,因为用户最大可用的带宽远小于整个集群的带宽,所以即使很多用户进行数据传输,吞吐量矩阵内数值也不会发生很大变化。
研究者使用 iperf3 测量了 TCP 的有效吞吐量,花了 4000 美金。下图展示了不同云服务提供商的网络延迟和吞吐量之间的关系。对于 GCP,我们利用内部 IP 来提高云内带宽。对于 GCP 和 Azure,云内路由的尾 RTT 比云间路由低。我们观察到,在 GCP 和 Azure 中,云间链接比云内链接要慢。由于 Azure 对出带宽没有限制,我们看到最快的云内连接达到了 16Gbps 的网卡容量。然而,GCP 和 AWS 分别在 7Gbps 和 5Gbps 时遇到了出口限流。

一个自然的问题是这个吞吐量矩阵要多久重测一次。下图展示了 AWS us-west-2 和 GCP us-east1-b 在 18 小时之内的吞吐量,每 30 分钟测一次。从 AWS us-west-2 出的云间和云内路由的吞吐量在一段时间内非常稳定。从 GCP us-east1-b 到 AWS 的路由同样非常稳定,但到 GCP 的云内路由入流量则不太稳定。不管怎样,GCP 地域之间的路径虽然有噪声,但是均值是一致的。因此,相对不频繁地(即每隔几天)对网络进行测量就足够了。在实践中,这些信息可以由第三方服务收集,或者通过主动测量来实现。
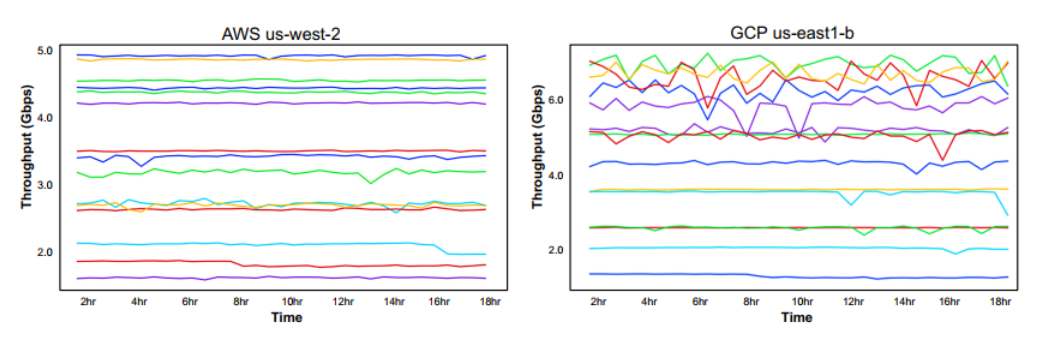
他图也没有图例,完全不知道在画啥。只能通过下面的对图的文字解释来理解,文章里这部分的表达也贼怪,反正中心意思是 GCP 大规模波动的原因是有传输噪声,均值是一致的,所以可以认为不会在短时间有大幅度改变。这里指的改变是指比如前一个小时是 10Gbps,后面就变成 5Gbps,到最后就 1Gbps 了的那种改变,波动是可以接受的,但是和 GCP 一样,要保证均值是一致的。所以不需要频繁测量,吞吐量矩阵在一段时间内是有参考价值的。
Principles of Skyplane’s planner
这部分没啥意思,主要就是介绍规划器的原则,比如怎么得到较低的实例和出口花费,并行 TCP 连接以得到高带宽,多 VM 并行得到高带宽。前面并行 TCP 连接是单机并行 TCP 连接,后面是起多个 VM,反正尽可能把带宽吃满。
Finding optimal transfer plans
这部分更没意思,全是整数规划的事情,反正就建图费用流,然后加上 VM 个数的限制,这个直接规约到混合整数规划的事情。只要这个是一个数学问题,那就没问题了。Nothing technical.
Implementation of Skyplane
使用 Python 实现,使用 AWS m5.8xlarge,Azure Standard_D32_v5 和 GCP n2-standard-32 实例。较小的实例会影响网络突发性能,我们希望能避免这种情况。
小虚拟机配的带宽小,他们希望都用大带宽的。
用户通过 Skyplane client 从他们的应用程序发起一次数据传输。client 根据传输计划在每个区域启动虚拟机,并在每个虚拟机上运行 Skyplane gateway。gateway 负责实际从源对象存储中读取数据,在覆盖网上转发数据,并写入目标对象存储。
启动 VM 的时间会影响传输延迟。为了减小 VM 镜像大小,他们使用了精简的系统,比如 Bottlerocket,然后用 docker 打包。
其实也不是什么延迟,文章里写的是 latency,主要指的就是传输时间。
Skyplane 假设对象已经被分成了大小差不多相同的文件 chunk。应用几乎可以无负担地处理这个问题。这使得 Skyplane 可以通过并行操作不同的 chunk 从云上快速读写文件。
这里举的例子是 TFRecords,感觉就像终于指出了目的是优化机器学习的数据传输。
为了减轻 TCP 慢连接的影响,Skyplane 在 TCP 连接准备好接受更多的数据时,动态地将数据划分到这些连接中。这与 GridFTP 等工具相反,后者是以 round robin 的方式将数据块分配给连接。这样做的缺点是,对于使用多条覆盖网路径的方案,每条路径上发送的数据量可能偏离计划时计算的目标,这可能导致传输数据的实际成本偏离规划器所预测的成本。
这里是要求每条路径就传这么多数据的,而不是谁快谁传的多这么规划。
为了避免中继区域的缓冲区溢出,Skyplane 使用逐跳流量控制,当一个虚拟机的队列中的块达到容量时,停止从进入的 TCP 连接中读取数据。对于 Skyplane 来说,类似 Bufferbloat 的问题不是一个问题,因为我们通过管道传输来优化吞吐量而不是延迟。
Bufferbloat 可能导致网络延迟抖动大。可以参考这里。
Evaluation
总之实验做了挺多的,每个方面都测了一下。感觉也没啥 technical 的地方。
Comment
感觉和原来的预印本相比,少了 Sky Computing,然后对 ML 的依赖没那么多了。主要文章改进的是价格和吞吐量之间的权衡,算是一个比较新的点。从用户视角来分析云服务的问题确实比较少,因为云服务整体是卖方市场,厂商主要聚焦的是云内的优化,云间的优化也是够厂商自己用就好,不怎么考虑用户的开销,相反也希望用户开销更大,所以说 Sky Computing 也很可能动了云服务商的蛋糕。主要是这种数据迁移的需求到底有多大还是未知数,之前老师让我看的时候还是为了算力网的覆盖网看,但是现在来看并不是十分符合覆盖网的需求,毕竟算力网的话只需要找一条吞吐量最大的路径就可以了,去掉费用的权衡剩下的就是一个最大流问题,但是这个问题已经有很多研究了,做个覆盖网控制面的事情。加上这种需求到底有多大,我觉得我是没有这种成天迁数据的需求的,可能也就用那么一两次,厂商一般也不会用,所以感觉是一个很方便的 tools,但是也不是那种非得用的那种。
虽然已经变成了天天需求需求挂嘴边的形状了,但是万一哪天割一下云服务商的韭菜,这个研究就十分有用了。但是就是不知道这个需求什么时候捶到我头上罢了。