Network Algorithmics 读书笔记
老板让我看两本书:Network
Algorithmics 和 High Performance
Switches and
Routers,搜了一下发现后一本书比较老,并且亚马逊上书评(两条)不怎么好,所以先看第一本了。
但是全英的,边看还要边复习英语,虽然也看过翻译过不少英文题,但还是有点崩溃。争取一天看一点,一周一更吧。
实际上中科大开了这门课:网络算法学,但是只有前九章,也就是前两个部分,有课件但是没有课程录像什么的。Harvey Mudd College 也开了这门课:CS181AG,有课程录像和课件,但是是英文的,还是看书吧……
个人评论用引用表达,就像这句话这样。个人观点可能有失偏颇,并且可能修改,请勿引用。
前言
网络瓶颈(network bottlenecks)是影响网络性能的主要因素之一。有两种瓶颈:资源瓶颈(resource bottlenecks)和实现瓶颈(implementation bottlenecks)。
资源瓶颈指底层硬件受限,比如处理器速度慢,通讯连接慢等等。但资源瓶颈可以灵活处理,花钱就能变强。
主要问题是实现瓶颈,下层硬件资源甚至是冗余的,上层程序跑得依然很慢。本书关心的就是这种瓶颈,特别是在服务器和路由器上的实现瓶颈。
本书旨在提供在所有网络上都能克服实现瓶颈的技术,并提供能够克服现在和未来网络瓶颈的准则和模型。
网络算法学(network algorithmics)是跨学科的,需要体系结构,操作系统,硬件设计和算法知识。网络算法学也是一个系统性的方法。
网络算法学这个名字是直译的,但是一些图论算法也被叫做 network algorithmics,我不确定是不是有更好的译名,只是遵从中科大课程的名字。但是可以肯定的是,网络算法学不仅包括算法,还糅合了实现黑魔法,不属于严格意义上的算法学研究领域。个人认为分为两部分:属于算法学研究的领域,和更高阶的算法实现技术(或技巧)。
本质上,本书讨论三件事:
- 基本的网络实现瓶颈
- PC 或服务器的瓶颈包括:数据复制,控制传输,多路复用,计时器,缓存分配,校验和和协议处理;
- 互联设备的瓶颈包括:前缀查询和精确查询,包分类,交换,测量实现和权限安全实现。
- 解决新瓶颈的基本原则
- 从基本原则出发,解决特殊瓶颈的方法
15 个解决网络瓶颈的原则
详细的解释在第三章,这里译名不同于第三章,是因为这是我凭直观翻译的,第三章的译名是中科大课件中的。
避免明显的浪费(Avoid obvious waste)
将计算变为时间(Shift computation in time)
关于这个原则的翻译我不好说,这个原则和原则 3.3. 的形式一致,但是翻译过来就怪怪的。这个原则主要针对一些可合并的操作,采用一些方式降低处理数据的时间消耗。
预处理(Precompute)
应用设备通道(Application device channels)
网上并没有什么介绍,我没听说过也不知道这是什么……
惰性计算(Evaluate lazily)
写时复制(Copy-on-write)
这也是一个比较通用的技术了,netpoll 的实现中也有,在无锁编程里也有这样的思想。其实和线段树 lazy tag 一样,用的时候再传标记。不过也是看场景使用。
共享代价和批次(Share expenses, batch)
集成层处理(Integrated layer processing)
因为把协议软件分层会导致性能降低,层之间不能容易地分享信息,这些层可能记录了冗余信息,协议头就会变大。因此可以选择把这些层整合成一层。RTP 协议是以这个原则设计的。但是这样直接打破了网络体系结构,我觉得可能是可以的,但是我不好说。关于翻译,由于多层共享同一个报文,处理报文的代价是共享的,处理时段是相同的,是谓共享代价和批次。
放松系统需求(Relax system requirements)
用确定性换时间(Trade certainty for time)
随机公平队列(Stochastic fair queueing)
我们实际上不太在乎确定性,发包快就行了,不必指定哪个会话用哪个发送队列。
用准确性换时间(Trade accuracy for time)
交换机负载均衡(Switch load balancing)
不懂为什么会失去准确性……并且也没搜到这是个啥,只有 Load-balanced switch。
将计算变为空间(Shift computation in space)
充分利用系统组件(Leverage off system components)
利用局部性(Exploit locality)
局部性驱动的接收器(Locality-driven receiver)
我先猜一个空间局部性,C 语言黑魔法系列又来了。但是关于这个接收器是啥搜不到……
用空间换时间(Trade memory for speed)
Luleå algorithm(Processing; Lulea IP lookups)
可能是打错了,这里应该指的是这种 IP 查询的算法。看上去主要用压缩 Trie 实现的。并且这里是真正的算法里说的用空间换时间,和原则 3.3. 是不同意思的。
使用已有的硬件(Exploit existing hardware)
快速 TCP 校验和(Fast TCP checksum)
意思是把 TCP 算校验和交给网卡去做,能省 CPU 时间。
添加硬件(Add hardware)
这里书里可能有 typo,hardware 多了一个 g,第一条的 pipelining 少了一个 g。
使用内存交叉存取和管线化(Use memory interleaving and pipelining)
管线化的 IP 查询(Pipelined IP lookups)
倒是有论文,但是没看出来用了什么新硬件,倒是设计了一个 bitmap。
使用宽字并行(Use wide word parallelism)
共享内存交换机(Shared memory switches)
这是啥玩意……
有效结合 DRAM 和 SRAM(Combine DRAM and SRAM effectively)
维护计数器(Maintaining counters)
因为 DRAM 和 SRAM 的速度和造价有很大差别。DRAM 造价低,但是存储速度慢,SRAM 造价高,存储速度快。相关问题复习计组,小丑竟是我自己。
创建高效专用过程(Create efficient specialized routines)
UDP 校验和(UDP checksums)
UDP 校验和与 TCP 校验和计算方法是类似的,TCP 校验和链接里也说了可以算 UDP 校验和,不太明白为啥单挑这个例子讲。
避免不必要抽象(Avoid unnecessary generality)
不要被参考实现束缚(Don’t be tied to reference implementation)
在层接口中传递提示(Pass hints in layer interfaces)
- 包过滤器(Packet filters)
在协议头传递提示(Pass hints in protocol headers)
标签交换(Tag switching)
可能指的是 MPLS
优化期望的情况(Optimize the expected case)
头部预测(Header prediction)
RFC 1185 的 2.3.2. 点提到了,但是里面引用的论文找不到了。
- 使用缓存(Use caches)
- Fbufs
添加状态以提升速度(Add state for speed)
活跃虚电路列表(Active VC list)
互联网上好像就没这个词一样……
增量计算(Compute incrementally)
重新计算 CRC(Recomputing CRCs)
CRC 是可以增量计算的,后续的影响可以直接补到前面,不需要重复算以前的部分。
优化自由度(Optimize degrees of freedom)
- Trie 上的 IP 查询(IP trie lookups)
使用桶排和位图(Use bucket sorting, bitmaps)
- 时间轮(Timing wheels)
建立高效的数据结构(Create efficient data structures)
- 四层交换(Level-4 switching)
第一部分:游戏规则
第一章 网络算法学简介
网络算法学和传统算法不同,网络算法学认识到采取跨学科的系统方法来优化网络实现这一要点,而不是只用优化算法就好了。
网络算法学涉及操作系统(加速服务器),硬件设计(加速如路由器的网络设备)和算法设计(设计可扩展的算法),并且是一个系统方法。
网络算法学解决的问题是基础网络性能瓶颈,网络算法学所倡导的解决方案是一套解决这些瓶颈的基本技术。
问题:网络瓶颈
本书的核心问题是如何让网络易用的同时实现裸硬件的性能。易用来自于强大的网络抽象,比如 socket 接口和基于前缀转发。但是如果不小心实现的话,这种抽象会产生比直接用光缆传更大的性能开销。
为了研究这个 gap,我们需要考虑两种网络设备:终端(endnodes)和路由器(routers)。
终端瓶颈
终端包括 PC 和服务器,总之是网络的终端节点。终端是专门针对计算的,而不是网络,通常被设计为支持通用计算。因此终端瓶颈有两个主要原因:结构和规模。
- 结构(Structure):为了运行任意代码,终端机的操作系统通常作为程序和硬件的媒介。OS 通常是分层的(比如有 HAL,资源管理层等等);OS 实现了一些保护机制(protection mechanisms),以防应用程序破坏;最后,核心 OS 进程(也就是内核态),比如调度器和内存分配器是用通用机制(general mechanisms)写的,这个机制面向尽可能广泛的程序。但是 OS 分层,保护机制和过度抽象可能严重拖慢网络程序,即使在最快的处理器上跑也会很慢。
- 规模(Scale):提供 Web 和其他服务的大服务器的出现导致了更深远的性能问题。比如 C10K,C10M 等问题。许多 OS 使用了低效的数据结构和算法,因为这些数据结构和算法是为连接数很少的时候设计的,太老了。
操作系统的结构和用户规模分别为内因和外因,同时制约网络性能。
我们将这些问题总结一下,如下表所示。
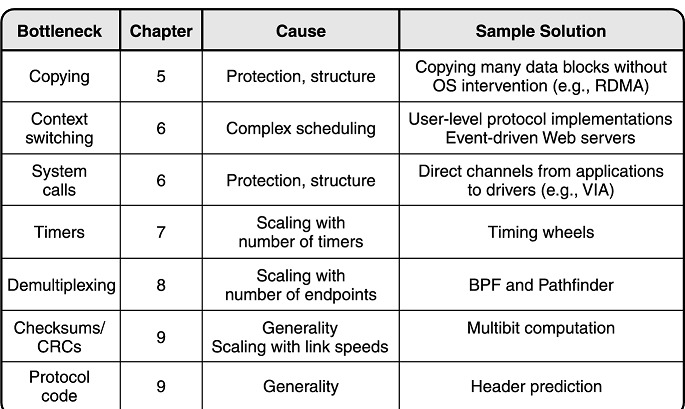
路由器瓶颈
路由器是针对网络环境设计的,因此结构的 overhead 很小,OS 十分轻量并且专为路由器定制,很多东西都用硬件实现。取代结构,路由器瓶颈有两个主要原因:规模和服务。
- 规模(Scale):同样有两方面规模
- 带宽规模(bandwidth scaling):光缆的传输速率越来越大,并且新应用程序越来越多,Internet 上的流量也越来越大了;
- 网络规模(population scaling):终端越来越多了。
- 服务(Services):Internet 提供的服务越来越多,提供网络保障(network guarantees)变得十分重要——拥塞中时延保障,安全保障和故障发生时的可用性保障。
问题总结如下表所示。
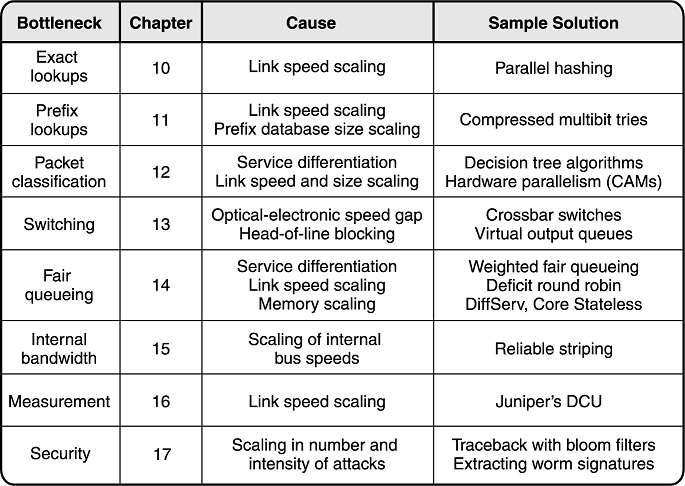
技术:网络算法学
当人们认识到 Internet 是一个由路由器和链路组成的系统时,可能就忽视了每个网络设备,比如从思科的 GSR(是思科的一款骨干网路由器)到 Apache 网络服务器都是系统。系统是由相互关联的子系统构建而成的,这些子系统在不同的时间点上被实例化。比如,一个核心路由器由带有转发引擎的线卡和被纵横式交换机连接的数据包内存组成。路由器的行为受到各种时间的影响,其范围从制造时间(当默认参数存储在 NVRAM 中时)到路由计算时间(当路由器协商计算路由时)到数据包转发时间(当数据包被发送到相邻的路由器时)。
事物是普遍联系的。
因此用系统方法的一个重要的观察是通常可以通过在空间上(即在其他子系统上)或在时间上(即在明显需要该功能之前或之后的时间点上)移动它的一些功能来设计一个有效的子系统。
这句话完全没有理解什么是在时间或空间上移动功能。原文如下:
Thus one key observation in the systems approach is that one can often design an efficient subsystem by moving some of its functions in space (i.e., to other subsystems) or in time (i.e., to points in time before or after the function is apparently required).
从某种意义上说,网络算法学的实践者是一个不择手段的机会主义者,愿意在任何时候改变规则以使游戏更容易。唯一的约束是整个系统所提供的功能要继续满足用户。
解决不了问题就换个问题,这是对的。解决问题可以用技巧,但是也可以靠力量。
考虑网络实现者在高速网络下面对的限制——越来越复杂的任务,需要支持更大的系统,小容量的高速内存和更少的内存访问次数——可能需要用尽实现技巧去跟上互联网日益增长的速度和规模。但是设计者可以直接加硬件,改变系统假设,设计一个新算法——反正任务是完成了。
热身训练:鉴别恶意数据包
这节书里是在上一节之下的,但是后续跟它同级的内容都从属与它,所以单将其设置为一个大标题,后续内容作为这一节下的内容。
考虑一个前端网络监视器(就当它是个防火墙吧),要设计一个标记入流量中的可疑包——这种包可能进行缓冲区溢出攻击,攻击者在网络头部
上学期刚做完缓冲区溢出实验这回又要防……
攻击主要原理就是缓冲区溢出导致注入的机器码(也可以是 shellcode)被执行。
其实未必要在防火墙层面上防,直接在设备上防开销已经不大了。
具体检查和防范的方法是,检测 URL
里包含的字符,因为要利用这个问题,势必 URL
会很长,并且大部分都是特殊符号(毕竟 shellcode 中大部分字符需要转成 URL
编码),比如 #。因此防火墙可以拦下这类包再进行检查。
当然有可能一些 CGI 脚本会被拦下,导致假阳性(false positive)的情况出现,因此我们假设有一个由安全工程师设计的规范被交给了芯片工程师。
这个例子是由 Mike Fisk 提出的问题。在面对这个问题时,我们从稻草人设计开始,一步一步优化这个设计,展示网络算法学的原则和技巧。
直观方案
芯片维护两个字符类型数组
所以整个算法过程就可以描述出来了。先扫一遍 URL,可以得到
假设数据包高速进入路由器,我们希望在下一个数据包到达前把这个数据包处理完,这个要求叫线速处理(wire-speed processing),这个要求在网络中很常见,即使在最坏的情况下,它也能防止处理工作的积压。为了满足线速,理想的芯片设计需要对于每个 URL 中的字节做尽可能少的处理。假设主要步骤中一次自增操作可以在收到一字节之前完成。
因为自增操作十分快,收到一字节需要进行信号转换,但是自增操作过 CPU 的速度几乎是瞬间的。
但是这个方案中,我们扫了两次数组,首先对数组清零,然后检查是否超过门限限制。最小的数据包大小经常大概
想想算法
直观的说,第二次扫
聪明的读者一定发现了,我们要判断的东西
这样我们砍掉了第二次扫描,虽然操作次数没变,但是我们还是砍掉了一次扫描。
到这里的思路是非常正常的,下面就是黑魔法时间了。
细化算法:利用硬件
我们优化了一次扫描,但是引入了除法。众所周知除法的电路逻辑十分复杂,算一次除法的周期比算加法长得多,我们怎么优化呢?
首先我们可以干掉浮点数,比如
这里每一次转化都很合理,但是放在一起可能有些不可理喻,但这就是黑魔法。
因此逻辑电路只需要实现移位和比较电路就可以了。状态存储只需要一个寄存器存
最快的芯片内部存储需要 1 到 2 纳秒读一次,但是更慢的内存可能需要 10 纳秒左右——这比逻辑电路计算的时间要慢。单门延迟在皮秒量级内,位移逻辑的门延迟时间并不高。所以瓶颈在内存访问上。
我们可以把
因为位操作比访存快,所以我们确实可以优化速度。
清理
说实话到这儿确实看起来不错,但是我们忘了一个最棘手的问题:我们忘了初始化
初始化最大值为
这时我们可以考虑惰性计算,反正我只关心
维护版本号并进行惰性初始化维护也很常见于各种算法竞赛的题目中,通常就是对一个很长的数组初始化很少的位置,直接 for 过去铁超时,所以用这种初始化。
由于版本号只是一个
这里考虑芯片设计中加入一个「擦除」循环,循环中读取这个数组,并且初始化所有过期的版本号。为了正确性,芯片必须保证在每八个数据包处理完之后进行这样的一次完整循环。考虑如果每个包有
这里有个假设,就是数据包都要过内存,也就是数据包要先存在内存里然后再被读取发出去。如果直接电路交换出去了,这个均摊是不成立的。但是应该确实所有包都要过内存的,毕竟要过转发队列的。
其实最简单的一种实现方式是:处理 8 个包后,芯片直接进入擦除态,这段时间里去访存擦除,但是这样是会形成时间毛刺的,这段时间没法处理包,虽然从数学意义上均摊了,但是不符合需要达到线速的要求。我们要把这段时间实际均摊到擦除过程中,而不是数学意义上。
那么芯片有两个状态:一个是处理 URL 的,一个是处理非 URL 的。当 URL
全部处理完后,芯片进入擦除态。芯片需要再维护一个寄存器
我们可以保证每 8 个包经过后每个位置都被这样重置一遍,所以每个位置记录的
可以认为都属于同一批 8 个包之内的,正确性是有保证的。
这样,我们用了
黑魔法部分终于结束了。
网络算法学的特点
网络算法学是跨学科的
- 跨学科的思维有助于产生出最好的设计
网络算法学认识到了系统思维的重要性
放宽要求(把门限百分比变成
的幂次)和将工作从一个子系统迁移到另一个子系统是极其常见的系统技术,但是教学上不教 这玩意过于 tricky 了,当然不会教。
「黑盒思维」不利于产生出整体或系统思维
毕竟我们在优化这个黑盒。
网络算法学从算法思维中获益
有一说一算法部分到变换到
的地方就停了,剩下的都是黑魔法,并且一般来说,这种变换也不叫新算法,算法中的 trick 罢了。
网络算法学的定义
Network algorithmics is the use of an interdisciplinary systems approach, seasoned with algorithmic thinking, to design fast implementations of network processing tasks at servers, routers, and other networking devices.
网络算法学运用跨学科的、系统的方法加上算法思维,为服务器、路由器和其它网络设备上的网络处理任务设计快速的实现。
上述中文定义摘抄自中科大网络算法学课件。
练习
设计一个卡方检验的有效实现。也就是计算
实际上还是一个路子,只不过上面变平方了需要化简
其中 是长度, 是门限。 是预期次数, 为实际次数。 然后接着拆
常数挪右边去,不等式变为 考虑我们维护的是左边部分的和, 每自增 ,对左边和式的贡献是 ,所以就差不多一样维护就行了,每次对和加上这个贡献。只不过这个题里维护和,例子里维护最大值,并且设计时需要考虑整数是带符号的,需要设计有符号除法移位。
第二章 网络实现模型
为了改善终端和路由器的性能,实现者必须知道游戏规则。网络算法学的中心难点包括以下四方面:协议,硬件结构,操作系统和算法。
但是做算法的不懂硬件,做硬件的也不懂协议,如果然他们合作的话会导致沟通困难。如果想要实现人员之间的有效沟通,可以从使用简化模型(simple models)开始,这个模型具有解释和预测能力,但没有不必要的细节。这个模型至少应该定义书中使用的术语,这个模型最好使得一个不属于此领域的创作者可以和属于此领域的创作者一起共同生产和设计。例如,一个硬件芯片的实现者应该能够对芯片驱动的软件修改提出建议,而一个理论计算机科学家应该能够想出 switch arbitration 的硬件匹配算法。
The switch arbitration problem is the problem of matching the inputs to the outputs.
应该可以翻译成交换仲裁
协议
运输和路由协议
应用程序把可靠传输的任务交给了 TCP。TCP 的工作是为发送和接收应用程序提供发送和接收的两个共享数据队列的模拟——尽管发送方和接收方机器被一个有损的网络分开。因此无论发送方无论向本地 TCP 发送队列里写了什么,接收方的接收队列里就应该按同样的顺序出现什么,反之亦然。TCP 通过报文分段和 ACK 机制实现,具体状态机可以参考下图。
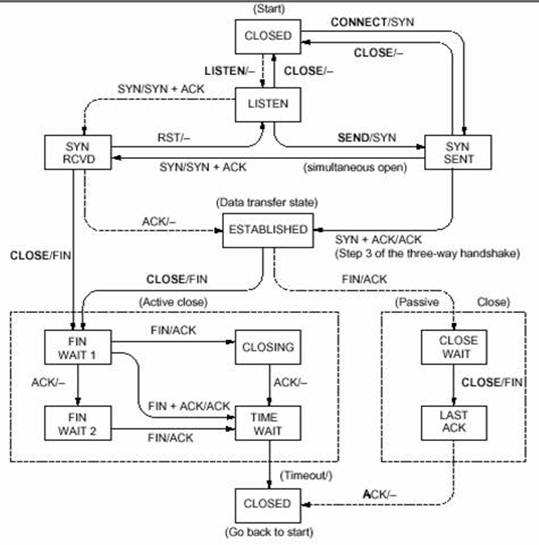
如果这个应用程序是视频会议程序,那么它会使用 UDP。
TCP 和 UDP 这样的传输协议通过从一个发送节点,跨 Internet 地将报文段发送给接收方的方式工作。实际上发送报文段的工作是 Internet 路由协议 IP 承担的。
Internet 路由分为两个部分,一个是转发(forwarding),一个是路由(routing)。
用熟悉的话讲,一个是数据平面,一个是控制平面。
转发必须在极高的速度下完成,转发表必须通过一个路由协议建立,尤其是在面对拓扑改变时,比如链路故障。有一些常用的路由协议,比如距离向量(RIP),链路状态(OSPF)和策略路由(BGP)。
抽象协议模型
协议是所有参与协议的节点的状态机,同时还有接口和消息格式。
A protocol is a state machine for all nodes participating in the protocol, together with interfaces and message formats.
更通俗的解释:协议由以下三部分组成:
- 语法
- 语义
- 同步
对协议的定义中,必须描述这个状态机如何改变状态和产生对接口调用,收到的消息和定时事件的应答(例如通过发送消息或设置定时器的方式)。
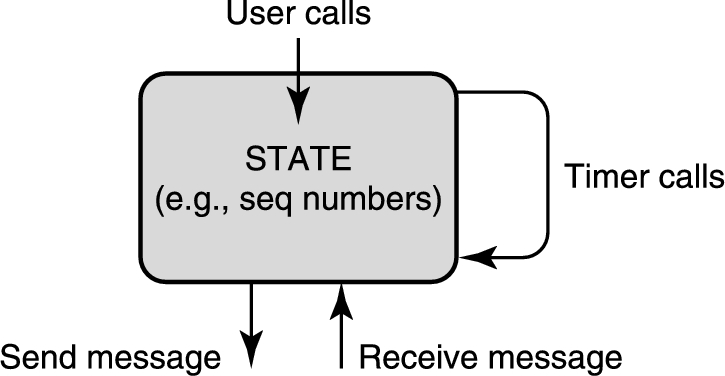
本书致力于协议实现,所以,抽象出协议状态机进行的通用且耗时的函数(generic and time-consuming functions)是值得的。如下模型将贯穿全书。
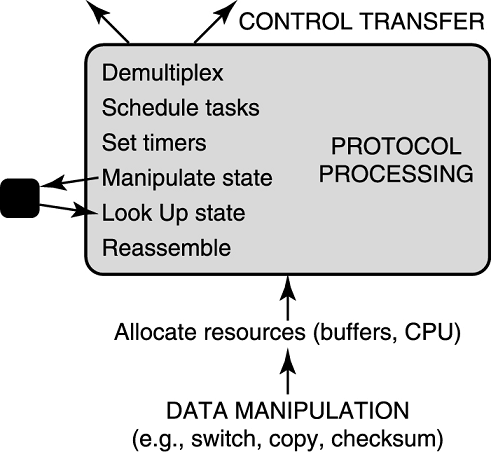
首先,在上图的下方,一个协议状态机必须接受和发送数据包。这涉及数据处理(data manipulations),或者说数据包里的每个字节都需要被读或写。比如,TCP 必须把接受的数据拷贝到应用缓冲区里,路由器需要把交换包从输入链路交换到输出链路上。TCP 头部中还有一个校验和字段,算校验和必须遍历包的每一个字节。
在图的上方,状态机必须向诸多客户端之一解复用数据。在某些情况下,客户端程序必须被唤醒,这可能需要潜在的高代价控制传输。比如,当 TCP 接到了一个网页,它需要使用端口号向浏览器解复用网页数据,这可能需要唤起启动浏览器的进程。
这张图同样包含了一些由很多协议共享的通用函数。首先,协议的关键状态都应该可以被高速查询,有时也需要高速控制。比如 TCP 收到包了,就引发 TCP 查询连接状态表,同样,收到了 IP 包就导致了 IP 去查转发表。其次,协议需要有效地设置定时器,比如 TCP 的重传机制就需要定时器。第三,如果一个协议模块为多个客户端处理数据,它就需要有效编排这些客户端。比如 TCP 需要调度不同连接的进程,路由器必须保证一些对计算机之间的通信不会锁住其他通信。一些协议允许大数据包分段,这就涉及分段重组。
虽然这些通用函数通常代价很高,但是他们的开销可以通过正确的技术来缓解。
性能环境和测量
本节介绍了一些重要的度量指标和性能假设。考虑一个系统(比如一个网络或者单独一个路由器),任务(比如消息)到来,处理和离开。在网络中最重要的两个度量指标是吞吐量(throughput)和延迟(latency)。吞吐量粗略地描述了每秒完成的任务数。延迟刻画完成一项任务的时间(通常是最差状况下的)。系统拥有者(比如 ISP)寻求最大化吞吐量以求最大化收入,同时系统用户想要端到端延迟小于几百毫秒。延迟同样影响了网络上的计算速度,比如 RPC 的性能。
在考虑实施权衡时,以下与互联网环境有关的性能观察是有帮助的。
链路速度:骨干网络速度已经升级到 10Gbps 和 40Gbps,本地链路也有 1Gbps。然而,无线网和家用链路要慢几个数量级。
现在已经可以向运营商购买 100Gbps 的商用专线了,但是高吞吐量的家用链路并没有普及,而且很贵。无线网的带宽有所提升,但是提升有限。
TCP 和 Web 的支配地位:Web 流量占 70%(字节数或者包数)。相似地,TCP 流量占 90%。
虽然举的是 1998 年研究的例子,但是运营商确实偏爱 TCP,对 UDP 连接时常 QoS,目前仍然是 TCP 作为主导流量。
传输量小:大部分访问的 Web 文档很小,比如一个 1996 年的研究显示 50% 访问的 Web 文件都不超过 50KB
这个研究可能旧了,现在 Web 技术日新月异,JS 大脚本会占用很多带宽,并且现在的带宽应该大部分是视频带宽了。
高延迟:实际的 RTT 已经超过了光速延迟,由一个 1995 年的研究,一个跨越美国的链接平均延迟为 241 毫秒,已经超过了光速延迟 30 毫秒。增长的延迟可能是由于提高吞吐量导致的,比如 modem 的批量压缩和路由器的管线化。
猫已经没了……并且通过一些努力,比如 CDN,访问延迟高的情况正在改善。
局部性差:对骨干网流量的研究显示 25 万个不同的起点终点对(也称为一条流)在非常短的时间内通过路由器。最近的估计显示大约有一百万条并发流量。将具有相同目的地地址的报头组聚集起来或其他方式并不能显著减少报头类别的数量。因此局部性,或者说在一个数据包中投入的计算在未来的数据包中被重复使用的可能性很小。
这里暗示网络流量的随机性很强。
小包:一项 1997 年的研究显示路由器收到的近半数的包是大小为最小大小 40 字节的 TCP ACK。为了避免小包丢包,大多数路由器和网络适配器制造商都致力于实现线速转发——这样就可以以输入链路的速度处理这些小包。
TCP 确实存在小包泛滥的情况。
关键指标:值得区分全局(global)性能指标和局部(local)性能指标,全局的性能指标比如端到端延迟和带宽,局部的比如路由器查询速度。虽然全局性能对于整体网络性能十分重要,本书只聚焦于局部性能指标。实践上,本书聚焦于转发性能和资源(比如内存和逻辑电路)测量。
工具:大部分网络管理工具聚焦于全局指标,比如惠普的 OpenView。本地测量所需的工具可以测量计算机内部软件的性能,比如做 profiling 的。例子有 Rational 的 Quantify,Intel 的 VTune 甚至硬件示波器。tcpdump 也很有用。
看 Rational 就犯 PTSD,属于被软工折磨的。
但是 tcpdump 是真的有用。
中科大的课件里还有三条组合分析,很有道理,摘抄于此:
- 高速链路+大量小包
- 包速率很高,到达间隔短;
- 线速处理难度大:处理一个包的时间必须非常短
- 高速链路+大规模并发流
- 数据局部性差,Cache 用不上(命中率低),消除访存瓶颈困难
- TCP 流占主导+TCP 处理开销大
- 优化 TCP 实现很重要
本节有一个案例分析,体现了协议特性可能极大影响程序性能,例子是 SAN 和 iSCSI 的,但是过于老了,现在真没听说过这俩东西了。同样中科大课件里也没有,于是目前从略。
硬件
正如链路接近 40Gbps 的 OC-768 速度一样,40 字节的包必须在 8 纳秒内转发出去。在这个速度下,包转发一般直接由硬件实现,而不是在可编程处理器上实现。但是搞软件的是不可能参与这样的硬件设计和开发的。接下来的一些简单模型可以让你快速入门。
Internet 查询通常用组合逻辑电路实现,Internet 数据包储存在路由器内存里,然后路由器将其和交换、查询电路放在一起,就组成了路由器。因此我们从逻辑电路实现开始讲起,接着讲内存,然后结束于基于组件的设计。更多细节可以参考 Introduction to VLSI Systems 这本书,还有经典的计算机结构教材 Computer Architecture: A Quantitative Approach。
组合逻辑电路
快速过一下数字逻辑的知识就可以了。只提供非门,与非门和或非门,任何有
例子 1 是为了实现 QoS 而实现优先级编码器(PE)。假设有一个路由器维护
实际上就是数二进制后缀
,直接被优化了。
计时器和功率
要把一个 40 字节大小的包以 OC-768 的速度转发,在这个包上进行的任何网络操作必须在 8 纳秒以内完成。因此在任意逻辑电路路径上,从输入到输出的最大信号传输延迟不能超过 8 纳秒。为了保证这个限制,需要一个晶体管内的信号传输延迟模型。
粗略地说,每个逻辑门,比如与非门或非门,可以想象成一组(当输入值改变时)必须充电的电容和电阻,这样计算输出值。更糟的是,给一个输入门充电可能引起后续输出门给未来的输入门充电。因此对于组合逻辑电路,计算函数的延迟是沿最差路径给每个晶体管充放电的延迟之和。这样的路径延迟必须适合于最小的包的到达时间。除给电容充电的时间之外,另一个延迟是线路延迟。
这部分应该是数字电路的知识,只需要知道这个延迟十分小,180 纳米制程的 CPU 通过单个逆变器驱动四个相同逆变器的输出负载的延迟是 60 皮秒就可以了。
为电容充能也需要能量,并且满足公式
现如今绿色计算越来越受到重视,这样的要求只会越来越多。
例子 2 要把这个优先级编码器用电路实现。有两种实现,第一种用
提高硬件设计的抽象等级
设计涉及到的晶体管数量可能超过一百万的网络芯片是十分耗时的。设计芯片也有一些技术。
然而,最重要的一点是,就像软件设计者复用代码一样,硬件设计者也复用常见的功能。
后面作者考虑了一个 74LS138 译码器和 74LS148 编码器的设计。在被数字逻辑狠狠地教育了一遍之后深感崩溃,毕竟只记住了一个 74181,而且上次看数字逻辑还是 2019 年的事情。
例子 3 考虑纵横式编排和可编程优先级编码器。例子 1
已经设计好了这个编码器。但是路由器里通常用的是增强版的可编程优先级编码器(PPE)。和之前一样,有一个
但是囿于捉襟见肘的数字逻辑水平和快崩溃了的心情,PPE 具体实现部分从略。
真的,看这部分有时候低头想,有时候抓头,有时候气笑了,跟精神病一样。
内存
在终端和路由器,包的转发用组合逻辑电路进行,但是包和转发状态存储在内存中。由于访存时间显著慢于逻辑电路延迟,内存形成了终端和路由器的主要瓶颈。
此外,不同的子系统对内存特性的要求不同。比如路由器厂商想要对包缓存 200 毫秒,这是 RTT 的上限,如果因为拥塞丢包了就从缓存里拿出来重试。如果在 40Gbps 的链路上,这样的缓存就需要大量空间。
大概需要 1GB 的缓存。
另一方面,路由器查询需要一块小内存,并且可以随机访问。这样对于不同的内存技术就需要一个简单的模型。
寄存器
寄存器是由触发器组成的,触发器是两个或多个晶体管通过反馈环路组成的,这样就可以储存信号了。逻辑电路访问寄存器是十分快的,大概 0.5 纳秒到 1 纳秒。
依靠双稳态电路内部交叉反馈的机制存储信息。
SRAM
SRAM(static random access memory)由
CPU 中的 L1 到 L3 缓存也都是 SRAM,容量各有大小,但是 L1 大小最小,L3 最大。
L1 缓存分为指令缓存 L1i 和数据缓存 Lid,和 L2 缓存为一个核心独享。L3 缓存是一个 CPU 中所有核心共享的。现在 Intel 搞的共享缓存是指 L3。
DRAM
一个 SRAM 中,存一个位要用至少 5 个晶体管。因此 SRAM
通常密度低并且很贵,通常做大容量内存的是 DRAM。SRAM 不需要刷新而 DRAM
需要定时刷新,几毫秒充一次电,但是 DRAM
存储密度高,结构简单并且造价低。DRAM
按行列组织存储单元,这样读取就需要经过片选,也就是行选和列选两个阶段。行列的编号规模是
注意连续的行选和列选之间有一个预充电延迟,这段时间需要给电容充电。
具体过程复习计组。
片上 DRAM 的访存延迟大约为 30 纳秒,最快的片外 DRAM 访存延迟为 40 到 60 纳秒,连续读的延迟约为 100 纳秒(由于预充电限制)。
页模式 DRAM(Page-mode DRAM)
一般来说 DRAM,或者说内存都是分页存储的。中科大课件中的翻译是快页内存,快页内存是 Fast Page-mode DRAM,但是和这里说的情况貌似没啥区别。
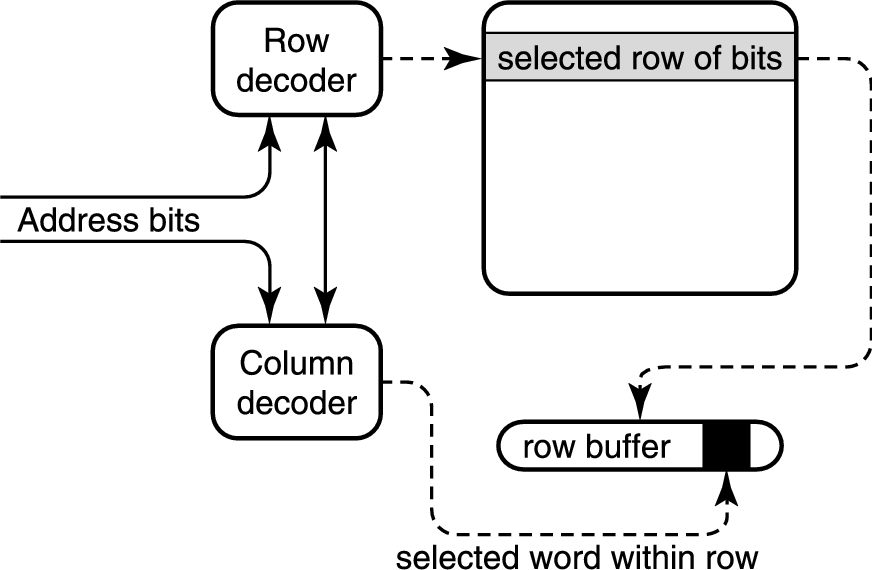
因为我们发现很多数组遍历操作一下子读取一行,那么我们可以考虑把这一行的内容都缓存一下,这种性质就是局部性。下图展示了一个典型的查询过程。由于我们缓存了一行,因此 RAS 预充电过程可以省略,这段延迟就没有了。显存直接把一行内容读进 SRAM,这样就可以高速串行读出刷新显示器。
交错 DRAM(Interleaved DRAMs)
内存延迟对计算速度有关键影响,同时内存吞吐量(通常称为带宽)也是十分重要的。假设一个内存的字大小是 32bit,一个周期是 100 纳秒。那么单次拷贝的吞吐量就限制在 32b/ns 这个速度。
大概是 3.725GB/s。现如今最新的 DDR5 的最大带宽大概在 70GB/s 左右。
显然,吞吐量可以使用访问多个 DRAM 来提升。在下图中,多个 DRAM(被称为 bank)被一条总线连在一起。
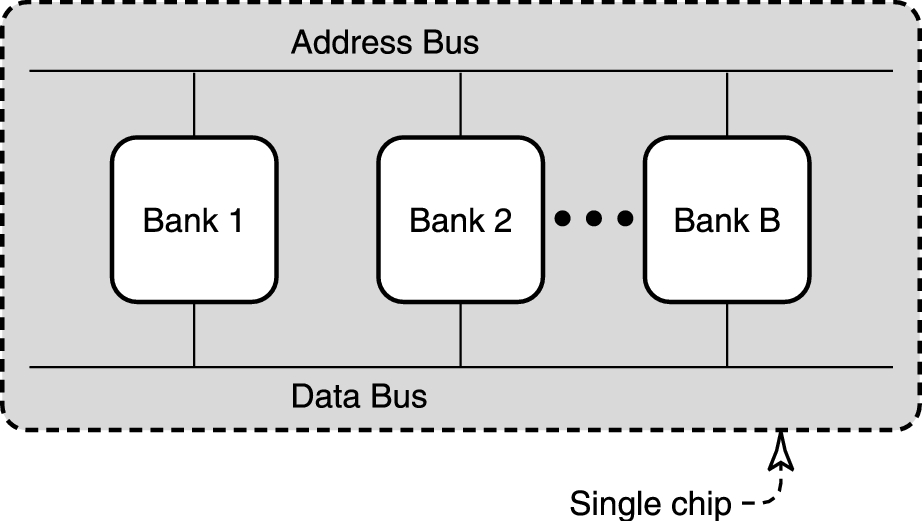
用户可以先把对 Bank 1 的读操作放在总线上。假设每个 DRAM 返回所选的数据需要 100 纳秒。那么在等待的这 100 纳秒中,用户可以把对 Bank 2 操作的地址放在总线上,以此类推。如果放一个地址需要 10 纳秒,那么在等 Bank 1 的结果的同时我们可以进行 10 个操作,这样就可以有效利用空闲时间而提高 10 倍的带宽,只要用户连续访问不同的 bank 就可以了。
目前的产品有 SDRAM(Synchronous DRAM,进化成了后来的 DDR)和 RDRAM(Rambus DRAM),SDRAM 集成了两个 bank,RDRAM 集成了 16 个 bank,但是 RDRAM 必须成对使用,现在已经退出市场了。
例子 4 考虑管线化流 ID 查询。一条流用源和目的的 IP 地址和 TCP 端口号来确定(也被称为网络四元组)。一些用户希望路由器跟踪每条网络流的发包数量,这是为了审计。这就需要一个数据结构存对于每个流 ID 的计数器。并且需要支持两个操作:插入和查询。这里的查询是精确查询,并且需要包来了就查。
到这里,要求还是比较简单的。用哈希或者开个 map 统计一下就好。
但是,如果我们要求实现线速,比如考虑最差情况,在 2.5Gbps 的 OC-48 速度下,一个 40B 的包要查流 ID,只预留了 128 纳秒。并且根据 1997 年的一项研究,核心路由器上预估有 100 万条并发流。
我们考虑使用平衡树,比如 B-Tree。为了速度,理想情况下应该把这棵树存
SRAM 里,但是要存 100 万个流,至少要
一个解决方案是用管线化,我们用一个 16 个 bank 的 RDRAM 存这棵
B-Tree,第
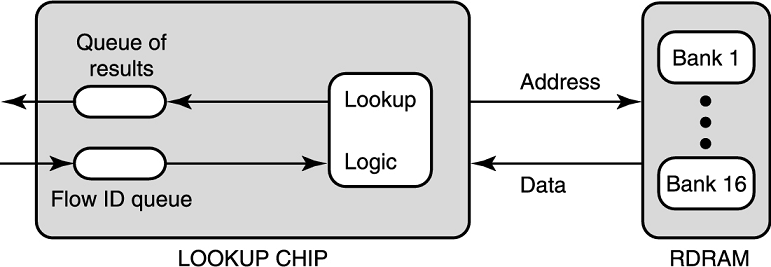
啥是 the time between address requests,能从运行频率算出来一个周期的时间是 1.25ns。
因此先需要
这里只考虑终端什么时候会吐出来一个需要 +1 的地址。
不幸的是,一个 16 层的二叉树只能存
内存子系统的设计技巧
- 内存交错和管线化
- 相似的技巧用在了 IP 查询,分类和调度算法中。多 bank 的技术可以用多个外部存储来实现
- 宽字并行
- 可以用 DRAM 的页模式或者字宽大的 SRAM
- 结合 DRAM 和 SRAM
- SRAM 昂贵且快,DRAM 便宜且慢,所以要平衡它们各自的优势。比如 SRAM 作为 DRAM 的缓存。
组件级别的设计
上两节中介绍的方法可以用于实现任意计算的状态机。一些关键芯片可能直接给路由器或者 NIC 设计,其余的设计就被称为组件级别的设计:比如组织和连接这些芯片,把板子放在盒子里的同时注意形状因数,电力和制冷。一个主要方面是理解针脚数限制,它通常提供一个快速的可行性检查。
例子 5 是考虑路由器缓存的针脚数。考虑一个有
使用
只看出来这种设计是有问题的,但是为什么只多一块芯片我不知道。因为肯定是要用 160 块 RDRAM 了,除非不用 RDRAM 否则不能避免这个 160 块的代价。
我们想说的就是针脚数是一个关键限制。
硬件设计经验总结
这个经验总结到 2004 年可用的经验。
太老了,也就图一乐。
- 芯片复杂度扩展
- 芯片速度
- 芯片 IO
- 串行 IO
- 内存扩展
- 功耗和芯片封装技术
网络设备结构
优化网络性能需要优化数据传递路径上的点。因此理解终端和路由器内部结构是十分重要的。实质上,终端和路由器都是状态机。然而,他们的架构为了不同目的而优化:终端架构为通用计算优化,路由器为 Internet 通讯优化。
终端架构
处理器是一个状态机,它接收指令和输入数据,然后把输出数据写到 IO 设备,比如打印机和终端。为了程序拥有较大的状态空间(指存储状态的空间),大部分处理器的状态存在廉价的 DRAM 中。PC 中这部分存储叫主存(main memory),通常主存用 SDRAM,但是 DRAM 访存时间很长,大概有 60 纳秒。
现在的 DDR 就是 SDRAM。
处理器使用缓存加速。比如 CPU 中的 L1 至 L3 缓存,它们都是 SRAM。缓存是一个内存地址和内容之间的哈希表。CPU 缓存使用一个简单的哈希函数:抽取一些内存地址位映射到数组,然后并行搜寻映射到数组内的所有地址。当一个内存位置需要从 DRAM 中读的时候,它会放在缓存中,然后缓存中的某个元素可能会被剔除。常用数据会存在数据缓存里,常用指令会存在指令缓存里。
如果指令和数据有时间局部性(即,同一位置会在短时间内多次复用)和空间局部性(即,访问一个位置之后下一次访问位置就在附近)的话,缓存的效果就很好。效果好的原因在页模式 DRAM 里写了。奔腾处理器会预先获取 128 个连续位(这也是一个缓存行大小),对相邻 96 位的访问不会产生缓存未命中的惩罚。
许多计算基准测试都有时间和空间局部性,然而,数据包流可能只有空间局部性。因此改善终端协议实现同上需要注意缓存的影响。
现在的计算机结构大部分采用总线式结构,如下图所示。
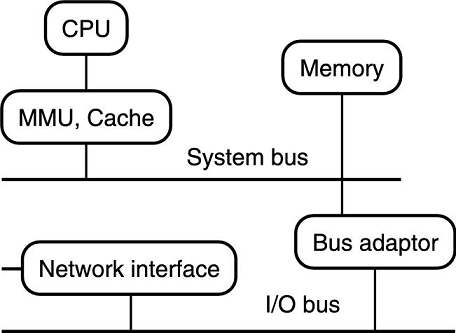
IO 设备通常通过内存映射,也就是开虚拟内存。比如网卡内存通常被映射到物理内存里,并占用一段地址。这就允许 CPU 和其他设备之间通过使用统一方式访存来进行统一通信。
现在大伙都用 DMA 了,原理还是复习计组,主要就是把 IO 的控制权从 CPU 中解耦,放到 DMA 上。
需要注意的是适配器通常位于与网络适配器和其他外设不同的总线上。内存总线为速度设计,并且为每个新处理器重新设计,IO 总线是标准总线(比如 PCI 总线),它会与旧有外设保持兼容。因此 IO 总线通常比内存总线慢。
一个经验是,网络应用的吞吐量被最慢的总线,通常是 IO 总线限制。更糟的是,协议处理通常涉及多次数据包拷贝,每个数据包都要穿过总线几次。
现代处理器使用把指令获取,指令解码,数据读写分省不同阶段的方式来高度流水线化。超标量和多线程处理器使用并发执行多指令的方式来加速计算。现在计算瓶颈已经没有了,但是数据移动瓶颈依然存在。
例子 6 考虑使用纵横式交换的终端结构。实际上就是把总线换成了一个可编程并行交换机。
路由器架构
高端(比如 Juniper 的 M 系列)和底端(比如思科的 Catalyst 系列)路由器模型如下图所示。
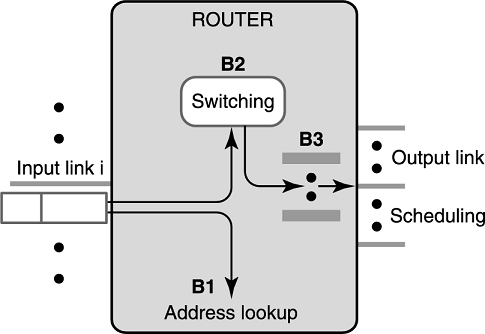
思科的 Catalyst 系列好像是交换机。
简单来说,路由器是一个带有一组输入链路和一组输出链路的盒子。路由器的任务是把输入的包根据目的地址交换到适当的输出链路上。我们将分析三个路由器的主要瓶颈:查询,交换和输出排队。
查询
如果一个包到达了输入链路
那么我们都知道转发包是按最长前缀匹配的,但是这是一个瓶颈。早期的路由器设计中,所有链路使用同一个共享的处理器,后来因为这个设计出现时间瓶颈了,所以变成每个链路都搞一个处理器做最长前缀匹配。最早的时候处理器用的是 CPU,后来在 Juniper M-160 里就用了 ASIC,提高了可编程性。但是之后用户又需要更多功能,比如负载均衡。因此一些新的路由器使用了网络处理器(network processors),这个处理器是专为网络设计的。
不是那个算神经网络的。
交换
之前的路由器是单总线交换的,这是一个巨大的瓶颈。如果我们有
于是目前最快的路由器内部使用并行交换架构,和例子 6 里的一样,用可编程芯片来做交换。但是编排交换就变得困难了,因为可能有很多输入链路会同时希望把包塞给同一个输出。这个问题会被分解成当每个包到达时,匹配可用的输入输出链路。这个问题在第 13 章会介绍。
排队
排队是一个古老问题了,面对拥塞我们目前只能排队。但是古早路由器是使用先进先出队列来实现的。现在的路由器使用随机队列来保证公平的带宽分配和延迟保证。
除了这些主要问题,下面还有一些次要问题。
头部校验和校验和
如果不保证头部是对的,那就可能出现头部信息错误,导致传输出现问题。所以我们需要对头部进行校验。校验和是可以增量计算的。这个校验通常在硬件里进行。
路由处理
路由用一些协议实现,比如 RIP,OSPF,但是这些路由器都需要实现 BGP。这些协议可能被一个或更多处理器实现。总之,都需要经过路由协商,计算和修改转发表这几个阶段。
早年间,思科因为不仅可以处理 Internet 包,还可以处理其他路由协议,比如 DECNET,SNA 和 AppleTalk 等路由协议而获得了很多市场份额,但是现在这个需求明显变少了。反而现在 MPLS 在核心路由器上需求比较大。
现在大伙都用 SRv6 了。
协议处理
所有路由器都需要实现 SNMP 并提供一些计数器可以远程审计。总之,需要提供远程管理接口。
分片,重定向和 ARP
虽然很明显,路由和协议处理最好交给所谓「慢路径」上的路由处理器,但有几个路由器的功能比较模糊。比如一个 3000 字节的包要发到 MTU 为 1500 字节的链路上,这个包就得分片。虽然普遍的趋势是由源节点而不是由路由器来做分片,但有些路由器在快速路径中做分片。
另一个功能是重定向发送。如果一个终端把消息发往了错误的路由器,这个路由器应该发送一个重定向(报文)到原来那个终端。
第三个是处理 ARP 请求,这个操作会在练习里说。
例子 7 是关于网络处理器的。也就是为了网络处理特化的 CPU。一些典型的型号比如 Intel 的 IXP1200。内部有 6 个核心,每个核心工作频率是 177MHz,时钟周期是 5.6 纳秒。
这个处理器最大的问题是将数据移入或移出 DRAM。IXP1200 需要 45
个时钟周期才能把 32 字节的数据从队列移到 DRAM 里,从 DRAM 移到队列需要
55 个周期。因为最小的包大小为 40 字节,从进到出就需要 200 个周期,也就是
1.12 微秒。所以转发效率大概是
后面还有一些黑魔法,但是仅限于大包场景,不细说了。
例子研究 2 是关于缓存和光交换的。现在光纤已经很常用了,核心路由器的逻辑电路和存储也称为了瓶颈。
毕竟是要过光电转换的,光脉冲转化为电脉冲需要一定时间。
那么我们能不能不过光电转换,直接从光脉冲里读出来 IP 地址并且做 IP 查询,然后把光脉冲存在光内存里?现在来看确实很难。
感觉过于赛博朋克了。
但是在一些终端之间实现光交换是可行的。因此,在热闹的光学领域的众多初创企业倾向于建立使用电子器件设置电路开关的光学电路开关。
鉴定为:炒热度,没啥卵用。
操作系统
操作系统是一个建立在硬件之上的软件,为了让应用开发者开发更容易一些。对于大部分 Internet 路由器,实时性高的包转发直接在硬件上跑,并且它不经过操作系统。不太时间敏感的代码在精简后的操作系统上运行,比如思科的 IOS。
操作系统提供了对硬件的抽象。面对硬件,三个核心难点是终端,内存管理和控制 IO 设备。为了解决这些困难,操作系统提供了三种抽象:不间断计算,无限存储,简单 IO。
一个好的抽象可以提高编程人员的生产力,但是有两个开销。首先,实现这个抽象的机制可能产生开销。比如调度进程可能会给 Web 服务器带来 overhead。第二,抽象可能隐藏了某些能力,阻止编程人员充分使用资源。比如,OS 的内存管理可能阻止编程人员把 Internet 查询的数据结构放在内存里,如果把这些数据放内存里可以最大化性能。
通过进程实现不间断计算
操作系统通过「进程」这种抽象来实现不间断计算。这种抽象通过三个机制来实现:上下文切换,调度和保护。
上下文和切换的过程如下图所示。

保护机制保证一个进程的非法行为不会影响其他进程。
具体参考操作系统。
进程有三种类型。
中断处理程序(Interrupt handlers)
用于紧急服务请求,比如有消息到达网络适配器
使用极少的状态,通常只使用几个寄存器
通常用于处理中断和恢复上下文
线程(thread)
- 轻量级进程,需要的状态比较少(因为线程之间共享内存)
- 同一进程之间的线程切换开销比切换进程小,因为内存不需要重新映射。
用户进程(user process)
- 使用机器的所有状态,比如内存和寄存器
- 切换上下文代价很大
例子 8 是 BSD UNIX 的接收者活锁。BSD UNIX 中,包到达会产生一次中断。这个中断是硬件信号(硬中断),这就使处理器保存目前运行的进程状态。然后处理器跳转到中断处理程序,这里绕过了调度器以提升速度。中断处理程序把这个包拷贝到内核中的 IP 包队列中等待消费,然后发起一个软中断后退出。假设没有更多(硬)中断了,中断处理程序退出,然后把控制权交给调度器,调度器调度处理器执行软中断,因为软中断的优先级高于用户进程。
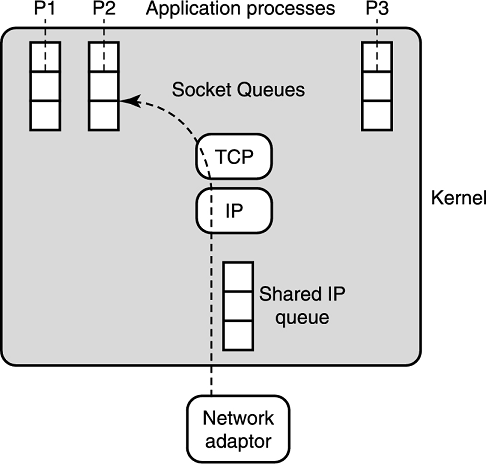
系统进程处理 TCP 和 IP 协议,然后把这个包发到适当的应用队列里,这个就是 socket 队列。假设这个应用是个浏览器。浏览器有一个进程是休眠的,并且在等待数据,那它现在就需要被调度器唤醒处理数据了。在软中断退出时,控制权传回给调度器,调度器可能决定运行浏览器,挂起一些其他的程序。
在高网络负载的情境下,计算机可能出现接收者活锁的情况,计算机会把所有时间花在处理到达的包,之后再把它丢掉,因为没有应用程序运行。如果有一系列连续的包到达,只有最高优先级的中断处理程序会运行,这就可能不会给软中断留时间,更不会给浏览器进程留时间了。因此要么 IP 队列或者 socket 队列会被塞满,塞满了就会丢包。
注意到终端节点中网络代码的延迟和吞吐量取决于「进程」的激活时间。比如,目前奔腾四上一个空的中断调用,中断处理延迟大约为 2 微秒,在一个具有两个进程的 Linux 机器上,进程上下文切换用时约 10 微秒,同一机器上 Windows 和 Solaris 上用时更多。这个时间看起来很小,但是在 Gbps 级别的以太网链路上,10 微秒内就可能来了 30 个最小大小的包了。
在端节点上,应尽可能减少中断和进程切换的发生。
通过虚拟内存实现无限内存
使用虚拟内存,编程人员可以直接把内存看成一个线性数组,由编译器指定变量位置。虚拟内存使用页表映射和请求调页两个孪生机制实现。
通常实现上一个页大小为 4KB,对于一个虚拟地址,高 20 位是页号,低 12 位是页内地址(也被称为页偏移量)。同样物理内存一个页也是 4KB。
虚拟页到物理页的映射关系被保存到一个页表中,以虚拟页号作为索引,这个就是页表映射。如果虚拟页不在内存中,那么当需要时就需要从磁盘读入到内存的一个物理页中,这个就是请求调页。
总之这个 OS 应该讲过。但是这样请求内存就多了一些操作,读一个内存位置可能需要访存两次:首先访问页表,把虚拟地址转化成物理地址,然后再去查物理地址。现代处理器通常用一个 TLB 来缓存最近的查询。实际上地址转换操作都是 MMU 负责处理的。
页表映射同样提供了进程之间的保护机制。当一个进程想读一个虚拟地址时,除非页表里有这个地址,否则硬件会产生一个错误。通过保证只有操作系统可以更改页表,操作系统可以保证一个进程不会在未授权的情况下读或写另一个进程使用的内存。
路由器是直接使用物理内存进行转发的,但是所有终端和服务器上的代码都使用虚拟内存。使用虚拟内存存在开销(比如 TLB miss),但也存在机遇。比如在 OS 和应用之间拷贝包就复制页表就好了。
通过系统调用实现简单 IO
让编程人员注意每个 IO 设备的多样性和复杂性是不能容忍的。所以 OS 把设备抽象为一块可读写的内存提供给开发者。
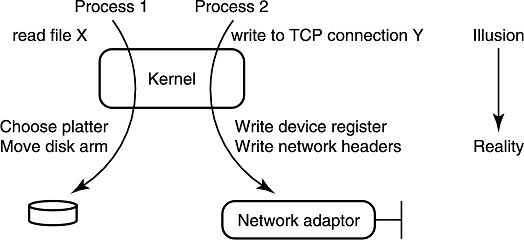
也就是万物皆文件。
把 IO 接口调用映射到实际的物理硬件的功能是由设备驱动程序做的。但比如硬盘的驱动需要被所有程序共享,而如果这样的话,应用直接调用这个驱动,出了问题的话很容易把硬盘(物理)干碎。安全的 OS 设计需要让这个程序 fail。
所以驱动程序需要在内核保护下运行。应用程序通过系统调用来进到内核态调用驱动。当函数调用返回时,程序从内核态回到用户态。系统调用比通常的函数调用更耗时,因为硬件权限提升和其他的函数参数检查等等都需要时间。一个普通的系统调用可能需要几毫秒。
与网络相关的是,当浏览器希望通过网络发送消息时,它必须进行系统调用以激活 TCP 处理。那么我们就希望优化掉这个状态转换,绕过系统调用。详细的在第六章。
总结
本章介绍了与系统性能相关的四个抽象级别,以及各个抽象级别上影响包处理速度的各种因素:
- 协议:数据操作、资源分配、协议处理等
- 硬件:存储器访问
- 体系结构:总线速度、缓存容量等
- 操作系统:进程调度和切换、虚拟内存、系统调用等
摘自中科大课件
练习
本章有七个练习。
TCP 协议和 DoS 攻击:
- 如何检测 SYN Flooding 等 DoS 攻击?请在路由器层面做。
- 你已经发现正在遭受 DoS 攻击,如何区分正常流量和攻击流量?
数字电路设计
- 设计两个输入的多路复用器
- 泛化本章的思路,用
输入的多路复用器设计 输入的多路复用器。并描述一个 门延迟且使用 个晶体管的方案 - 如何使用规约到多路复用器来设计一个桶形移位器(即,用多路复用器实现一个桶形移位器)。基于你的设计,请说起你设计的门复杂度和时间复杂度。
- 试着在晶体管级别设计一个桶形移位器。时间复杂度和晶体管复杂度各是多少?
一元编码:设计以下 4 位输入的数模转换器的数字逻辑(即,一元编码)。输入是一个数
,输出是 。如果这个数的值为 ,那么 ,其余为 。请用与或非门实现这个数字电路。 先写出
到 ,然后用卡诺图化简。 内存设计
内存和管线树
架构,缓存和更快的哈希函数
操作系统和懒接收者处理:为了改善接收者活锁,采取了以下两个措施:
把共享的 IP 处理队列换成每个接收 socket 一个。为什么这个可以起作用?为什么不好实现?
这个方法没改善锁吧……撑的时间明显提高了,但是队列的消费还是被高优先的硬中断和协议处理锁了。并且多队列管理和 socket 的缓冲区管理也提高了实现难度。
第二种机制是在接收进程的优先级上实现协议处理,并作为接收进程上下文的一部分(并且不作为分开的软中断)。为什么这个可以起作用?为什么不好实现?
锁放在真实消费上应该可以解决这个问题。可能需要注意不能变成串行的,就是硬中断之后直接接一个软中断处理包然后 notify 程序,中间需要安排其他调度。
第三章 十五个实现原则
第一节 使用原则:更新 TCAM
如果一个字符串由 0,1 和 *
组成,就称这个串是三进制的。* 是通配符,可以匹配一个
0 或一个 1。
内容可寻址存储器 CAM 是一种存储长度确定的三进制串和它对应信息的内存。可以理解为一个 KV 存储器,扔过去一个三进制串,它可以并行地在一个周期内找到和三进制串匹配的最低内存位置。
我们可以考虑利用 TCAM 这个匹配特性加速 IP
转发查表的过程。这里我们需要规范一下,假定 * 可以匹配任意个
0 或 1。找 IP
转发是找最长前缀匹配转发,所以通配符只出现在结尾,根据 TCAM
的特性,我们需要将这些前缀按照从长到短的顺序从低地址到高地址排布。
但是路由会经常添加或删除前缀,一个朴素的方法就是
理解并利用自由度 / 使用算法
因为一起写比较直观,并且逻辑十分通顺,所以合一起写了。
我们定义的时候只说需要将这些前缀按照从长到短的顺序从低地址到高地址排布,没说长度相等的前缀应该怎么排,所以我们考虑就随便排,这样插入只需要插到这个长度区就可以了。这就是理解自由度。
因为 IP 长度最长就
同样的,删除也是可以这样递归地做的,比如我们找到了这个表项,它的长度为
分析复杂度,我们只是依次枚举了小于等于
但是分析一下细节,如果我们的
至于为什么不搞
个自由位置区,个人认为是管理比较困难,又需要增加维护偏移的复杂度,像堆和栈一样对顶维护自由位置区不需要引入更多东西,直接自由扩展就可以实现了。并且还能达到优化的目的,这是值得的。
还有一个比较隐蔽的自由度是「将这些前缀按照从长到短的顺序从低地址到高地址排布」,由于
CAM
是找第一个匹配的位置,而且我们做的是最长前缀匹配,所以为了方便我们这样规定。但是比如
010* 这样的前缀是可以出现在 11001*
前面的,因为这这两个前缀都不是对方的前缀,所以我们重新规定「如果两个前缀
但是这不是唯一的方式,上面这种方法使用了 P3,也就是放松系统需求的方法,当然还可以使用其他方法。
第二节 算法 vs 算法学
我们用下面这个例子来说明算法和算法学之间的区别。
在许多入侵检测系统中,一个管理层时常根据某些统计特征检查发现某个流(被某些包头部,比如源
IP
表示)可能有问题。比如,一个源地址做端口扫描可能会给一个子网的不同机器上发
虽然有一些方法来识别来源,但是证据(也就是发出来的那么多包)通常在确定某个源是有害的时候就消失了(转发走了)。问题就在于做这种统计学检查的时候需要对每个包收集一些状态(比如存在怀疑表里),并且保存一段时间,直到这个源被认定为可疑。因此,如果一个源在 10 秒后被认定为可疑,如何回退并检索在这 10 秒内这个源发的包呢?
这项任务通常被叫做网络流量取证。
为了完成这项任务,可以按下图的方法存储路由器最近发送的 10 万个包。当包转发时,我们把一个包的拷贝塞到队列里(或者就塞进去一个指针)。当队列满时,我们从头弹出包。
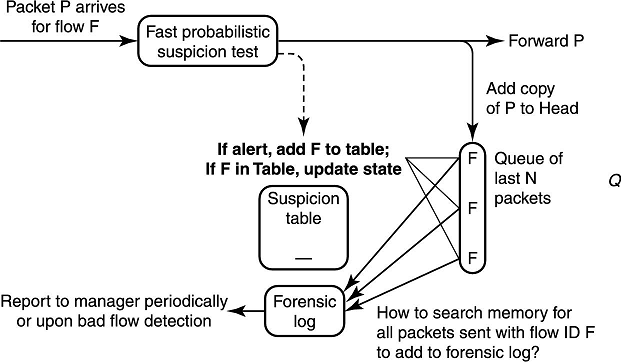
书里是把包往头上塞,从尾弹,意思都一样。
主要问题就在于,当探测到一个可疑的流时,可能在队列里有很多个流的包。这样我们就要在队列里把这个流的包找出来打 log,因为这个队列存在 DRAM 上,所以找起来十分耗时。
教科书上的算法告诉我们可以给流 ID 加一些索引结构来加快查询。例如,可以维护一个流 ID 到队列里这个流 ID 对应的每个包的哈希表。当一个新包进来时,在哈希表里插入流 ID 和这个包的指针的 KV 对,当然,离开队列时要删除这个 KV 对。
这个方法看起来是可行的,但是它有些难点。它增加了额外的空间来维护这个哈希表,而对于高速实现,空间是很宝贵的。这个方法也增加了额外的时间复杂度来维护哈希表,并需要在数据包被 10 万个数据包之后到达的数据包覆盖之前,将一个流的所有数据包写到 log 里。与之相比,下面这个方案更优雅一些。
当一个流被标识为可疑时,不去立刻把队列中所有这个流的包都拿出来,而是延迟鉴别它们,直到它们要出队列了再检测它们是不是属于可疑流的包。如下图所示,我们维护一个可疑流的列表,如果判定一个流是可疑的,我们就把这个流 ID 扔到这个列表里。每当出队列一个包,我们就判断这个包的流 ID 是不是在可疑列表里,如果在,就把它打到 log 里。这样我们不需要哈希表,存储空间需求也大大降低了。
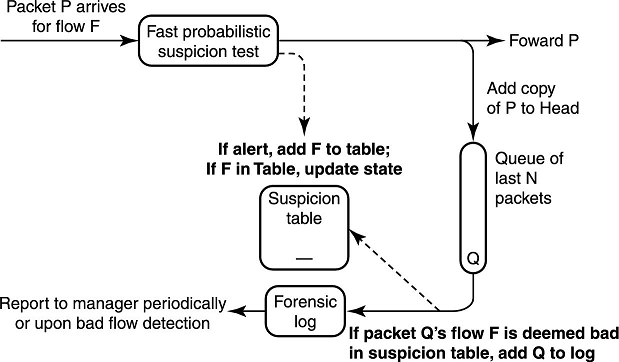
但是假设,发了 10 万个包之后这个路由器就不转发了,那队列就不会出元素,所以这样如果有一个恶意流,这个流就一直不会打 log,所以这种方法应该实时性不是很好。但是路由器转发一般不会停,这种情况太极端了,所以一般情况下应该是可以满足要求的。
第三节 十五个实现原则——分类和描述
十五个原则可以分类成以下类别:
- 1-5:系统思维
- 6-10:保持模块化的同时恢复到裸硬件的效率
- 11-15:加速关键步骤
系统思维
P1:避免常见情形中的明显浪费
系统中可能在一些特殊的操作序列中有浪费掉的资源,如果它们有相同的 pattern,就可以消除这个浪费。
比如你要做冰激凌就要去仓库拿冰激凌机,要做馅饼就要去仓库拿托盘。你要同时做这俩,就不需要去两次仓库,去一次仓库把这俩东西一起拿来就行了。
再举个例子,比如编译器面对如下两条先后执行的语句:
一个经典的网络中的例子是避免一个包在 OS 和用户缓存中多次拷贝,也就是通过零拷贝技术避免不必要的包移动。
需要注意每个操作(比如去仓库,一行代码,一次包拷贝)自己都不认为是一次浪费。是一系列操作(两次去仓库,两行代码重复计算一个子表达式,两次拷贝)有明显的浪费。
这告诉我们系统优化具有局部相关性,而不在于单条语句是否可以优化
显然,暴露的环境越大,优化的范围就越大。虽然识别某些值得优化的操作模式往往是设计者的直觉问题,但优化可以在实践中使用基准进行测试。
P2:在时间轴上移动计算
系统有时间和空间两个方面。空间方面用子系统来表示,可能是地理上分布的,系统被分解成这些子系统。
子系统可能是地理上分散在各个地方的,这本书一堆长难句,读起来靠意会,佛了。
时间方面由一个系统在不同的时间尺度上被实例化的事实表示,从制造时间到编译时间到参数设置时间到运行时间。通过在时间上转移计算,可以获得效率提升。
就是我们把计算从某个时间段移动到某个时间段,比如就不要一堆任务往一个时间段里放,这样会导致一个时间段内任务处理不过来,负载很大,均衡地在一些时间段内放合适的任务,这样就可以减小最大开销,提升系统性能。
只能说这段写得贼抽象,写得挺好,下次别写了。
下面是属于时间转移的三种通用方法。
P2a:预先计算。指的是在使用这个值之前先把它算出来,以节省用的时候计算的开销。比如你可以提前切好葱姜蒜,然后再炒菜,而不是炒菜过程中切葱姜蒜。一个通常的系统例子是查表法。比如在运行时计算
函数是十分耗时的,我们可以预处理出这个函数域中所有元素的函数值,放到一个表里,然后运行时查表就可以大大降低耗时了。一个网络的例子是提前计算一个连接中的 IP 和 TCP 头部,以减少写包头的工作量。 也就是预处理。
P2b:延迟计算。指的是推迟在关键时间上要执行的高代价操作,并且希望这个操作后续不会需要,或者找到空闲的时间段来执行。比如一家饭店可以把刷盘子这个任务放在一天最后来进行,而不是来一个盘子就放下手头工作刷一个。预先计算是在需要之前计算,延迟计算是只在需要时计算。
相当于打 lazy tag,还是那个例子,因为盘子越用越少,当不得不洗盘子的时候还是得洗,但是没必要来一个洗一个。
一个较为著名的延迟计算的例子是 COW,假设我们要把虚拟地址
的内容移动到虚拟地址 上。一个通用的方法是直接复制,但是 COW 直接把页表中 的虚拟地址的内容空间指向 。当对 写入时,再复制出相应的内存页供 写入。因为我们期望写入 的页和总共的页面数相比很少,这样就避免了不必要的拷贝。 一个简单的网络上的例子是当网络包到达终端
时,发现这个包的字节序和终端机的字节序不一样。我们不需要立刻调整字节序,而是实际要读取这个包的时候再调整字节序。 P2c:分摊开销。这指的是充分利用系统中其他部分执行的高代价操作。一个重要的例子是批处理,一些高代价操作可以一起进行,这样就比分开进行的代价更低。比如烤馅饼没必要一个一个烤,而是可以把要烤的一起烤。计算机系统使用批处理技术已经很多年了,尤其是在大型机的早期,在分时复用之前。批处理换延迟为吞吐量。一个简单的网络上的例子是时间轮,计时器数据结构与更新时钟的例程共享高代价的每钟点处理进程。
应该指的是定时任务管理进程,这部分中科大课件给的例子是网卡在收到一批包之后,再产生中断,在多个包之间分摊中断处理的开销。感觉这个更贴切一些。
P3:放宽系统要求
当一个系统自顶向下设计的时候,各个函数就被子系统分割开了。在修复了子系统需求和接口后,独立的子系统就被设计完成。
放宽系统要求有下面三个技术:
P3a:牺牲确定性换时间
系统设计师可以不保证系统的确定性,事实上我们都基于概率。比如量子力学告诉我们你身体里的原子会重组而形成一个冰球,但是这显然是不可能的(引用 Tony Lauck 的话)。这使我们当确定性算法太慢的时候考虑随机化算法。
系统中,当拥塞发生时就使用随机化发包。一个简单的例子是思科的流量测量软件 Netflow:如果一个路由器没有足够的能力对所有来的包计数,它可以随机采样,并且仍然能够从统计学上识别大流量。第二个例子是随机公平队列,每个会话用哈希依概率追踪,而不是准确追踪一个会话。
P3b:牺牲精度换时间
同样地,数值分析告诉我们计算机不是完全准确的。因此可以考虑牺牲精度换时间。比如 MPEG 等图样压缩算法使用 DCT 来压缩图片,而不是使用插值,这牺牲了精度(图像有损失),但是计算速度更快。第一章里我们使用近似的门限值,以将除法变成移位。
今天才意识到,门限好像应该翻译成阈值……
在网络中,在路由器的包编排算法会将包按发送 ddl 排序,这里的排序可以做近似排序,以在满足 QoS 的情况下不会增大 overhead。
P3c:在空间中移动计算
注意这些例子都放宽了限制:采样可能会遗漏一些包,传输的图片并不一定和原图完全一样。然而,系统的其他部分需要适应这些放宽的限制。因此我们更愿意把这个想法称为在空间中移动计算,意思是把计算从一个系统移到另一个子系统(拆东墙补西墙)。
比如 IPv6 的分片,通过让终端计算出能通过所有路由器的数据包大小,避免了路由器对数据包进行分割的需要。
这里,我们需要预先计算能通过所有路由器的数据包大小,实际上也增加了复杂度。
中科大课件中还有一条将协议处理从内核子系统移动到用户空间,这避免了状态切换,可以减少时间。
P4:利用系统组件
系统设计中的黑盒视角是将系统分解为一些子系统,然后独立地设计这些子系统。这种自顶向下的方法具有十分令人满意的模块化特性,但是实践中性能要求极高的组件通常自底向上设计。比如,通常是让算法适合硬件。以下是此原则下的三种技术:
P4a:利用局部性
第二章中显示如果数据在内存中是连续排布的,那么硬件可以提供加速,比如在硬盘的同一个删去,或者 DRAM 在同一个 DRAM 页中。硬盘搜索算法就使用了高 radix 的搜索树,如 B-Tree 来利用这个特性。
radix 指的是基数,应该指的是树的一个节点代表了一段连续的存储空间。
在 IP 查找算法中同样使用了这个性质,将一些 key 存储在一个宽字中来减小查找时间。就像我们一个 SRAM 宽字里存了
三个值一样。 利用局部性可以更有效地利用 cache 来加速算法。比如循环展开什么的。
但是学了这么长时间其实也就会一个循环展开了……
P4b:用空间换速度
一个显然的技巧是使用更多的内存,比如一个查找表,来节省处理时间。一个不太显然的技巧是压缩数据结构让他更适合放 cache 里,因为访问 cache 比访存快,在这种情况下,内存和速度都会有所改善。Lulea IP 查找算法就使用了散列数组,使用空间优秀的 bitmap 可以十分高效地查找 IP。
P4c:利用硬件特性
编译器使用强度削减优化来消除循环中的乘法运算。例如
1
2c = 5;
for (int i = 0; i < n; i++) x[i] = c * i;编译器可以优化成
1
2c = 5; k = 0;
for (int i = 0; i < n; i++) x[i] = k, k += c;这样乘法就可以被优化为加法了,这极大地提高了效率。IP 校验和算法也是这么算的。
IP 校验和中不需要乘法,但是还是可以很快地实现,见这里。
但如果这个原则使用过多,系统的模块化将难以保证。有两个技巧可以减轻这一问题。首先,如果我们利用其他系统特性只是为了提高性能,那么对那些系统特性的改变应当只影响性能,不影响正确性。第二,我们只对对确认为是系统瓶颈的组件运用该原则。
中科大课件:对系统的优化要有一定的度,应当只对系统做最小的修改,不提倡大刀阔斧地改!
我认为我们应该首先对黑盒进行这样的优化,然后再考虑对黑盒之间的部分进行这样的优化。
P5:添加硬件改善性能
当以上所有方法都失效时,使用暴力方法。添加新硬件,比如买更快的处理器,可能是比使用更聪明的方法更简单也更节约代价的方法。除了使用更快的基础设施(比如更快的处理器,总线,连接等等)这种暴力方法以外,还可以更聪明地权衡软硬件来实现。因为硬件不那么灵活,设计成本更高,所以只增加最少的硬件是最好的。
在计算机系统领域,每年都会出现一些奇迹般的改进,比如在处理器的速度和存储密度上,所以大家都软件中进行关键算法,然后升级到更快的处理器,以获得更快的速度。但是,计算机系统中更巧妙的软硬件权衡比比皆是。
比如,在多处理器系统中,如果一个处理器希望写数据,它必须通知任意缓存了这个数据的某个版本的「所有者」。如果每个处理器都有一个硬件来观察总线上其他处理器的写事务,并在必要时自动使缓存位置失效,那么这种交互是可以避免的。这个简单的硬件嗅探缓存控制器允许缓存一致性算法的其余部分在软件中有效执行。
将函数在硬件和软件之间专业也是一种艺术。硬件有一些好处。首先,接收指令不需要时间:指令是硬编码的。第二,通常的计算序列(可能在程序中需要一系列指令)可以在一个时钟周期内完成。比如,查找 32 位数的最高位在哪儿,在 RISC 机上需要一些指令,但是用一个优先级编码器可以十分简单地算出。
第三,硬件允许你明确地利用问题中固有的并行性。最后,批量制造硬件比通用处理器便宜。比如一颗奔腾处理器可能要 100 美金,但是批量制造一批速度相似的 ASIC 可能只要 10 美金。
另一方面,软件设计可以轻松地转化为下一代更快的芯片。硬件方面,尽管使用了可编程的芯片,但仍然不太灵活。但尽管如此,随着设计工具的出现,如 VHDL,硬件设计时间已大大减少。因此最近几年执行复杂函数的芯片,比如图像压缩和 IP 查询的芯片,都已经被设计出来了。
除了一些特定的性能提升,新技术还可以导致完全的模式转变。在这种趋势下,一个有远见的设计师可以完全重新设计一个系统。例如,晶体管和快速数字存储器的发明无疑使电话网络中的数字化语音得以使用。
应该指的是语音通话,这是一个模拟信号转化为数字信号传输,再转化成模拟信号的过程,有了晶体管和存储器才能做到。
芯片密度的增加使得计算机设计师们开始思考在存储器中增加哪些特性以缓解处理器与存储器之间的瓶颈。在网络中,20 世纪 80 年代的高速连接的使用导致了大地址和大头部的使用。讽刺的是,90 年代笔记本电脑的出现导致了低带宽的无线网络的使用,这样出现了头部压缩的需求。技术趋势会像跷跷板一样。
以下是在网络 ASIC 中常用的技术。它们在第二章时第一次出现,这里重提一下。
- P5a:使用交织内存和流水线,提高查表速度
- P5b:使用宽字内存,提高访存效率
- P5c:结合 DRAM 和 SRAM,兼顾大内存和访问速度
中科大课件中的补充:
对硬件与软件的传统看法:
- 硬件灵活性差,设计周期长,适合完成简单、固定的功能
- 软件灵活性好,适合完成复杂的功能
可重构计算的出现使得以上界线变得模糊:
- 动态可重构 FPGA 既有硬件的执行速度,又有软件的可编程性,设计工具的出现使得硬件设计周期大大缩短
今年 OSDI ’23 中 IPADS 一个重新设计虚拟机的工作就是利用了 P5 这个技巧,增加 FPGA 硬件,用 RISC 里的虚拟化扩展重新搞了一遍虚拟机,十分震撼。
兼顾模块化和效率
一位读过 Dave Clark 关于分层实现效率低下的经典文章(比如这篇)的工程师曾经向一位研究人员抱怨过模块化。这个研究者回复说:「但就是这样,我们才走到了可以抱怨的阶段。」当然,她的观点是,像网络协议这样的复杂系统只能通过分层和模块化来设计。以下是从 Clark 和其他人的工作中摘取的原则,显示了如何在保留模块化的同时重新获得效率。
没有模块化就没有大型系统,这是软件工程给我们的启发。现实问题并不是我们不要模块了,而是如何设计,组合和拆分模块,让模块之间高效交互,以获得高性能。
P6:用高效的定制例程代替低效的通用例程
就像在数学中一样,在计算机系统中使用抽象可以让系统紧凑,正交和模块化。
正交应该指的是松耦合。
但是有时通用例程的「一刀切」也会导致效率低下。在重要场景下,应该注意设计一个定制的优化例程。
比如数据库缓存。大多数通用缓存采用 LRU 策略。但是考虑一个查询处理例程在一次循环中处理一系列数据库元组。这种情况下最近使用的记录在未来会使用得最多,所以它是理想的替换对象。
意思应该是在这种循环中循环过了之后一段时间不会再访问,所以缓存它没用。
所以最好针对关键例程定制优化策略来避免代码膨胀。
P7:避免不必要的通用化
中科大课件里的是一般性
设计抽象和通用子系统的倾向也会导致不必要的或很少使用的特性。因此,与其建立几个专门的例程(如 P6)来取代通用例程,我们可能会移除一些特性来提高性能。
图灵奖获奖者 Butler Lampson 提供了两个引述:「当有疑问时,就把它去掉」(来自匿名者)和「消灭特性」(Thacker)
原文为 When in doubt, get rid of it 和 Exterminate Features。
当然,就像 P3 的情况一样,去除特性就需要常规的函数在限制中运行。比如 RISC 处理器去掉了复杂指令,比如乘法这种指令就要在固件中模拟。网络中的例子比如 Fbufs 提供了定制的虚拟内存服务允许在虚拟地址空间中高效拷贝。
中科大课件中还有以下例子:
- 针对路由器定制操作系统
- 针对 Web 服务器定制协议栈
P8:不要受参考实现的束缚
编写规范是为了明确编写方式,而不是建议的有效实现。由于抽象的规范语言不受欢迎,许多规范使用了诸如 C 的命令式语言。人们获得的是规定如何计算该函数的代码,而不是要计算的函数的精确描述。
规范应使用专门的规范语言书写,只描述要做什么,不包括怎么做。现实生活中,许多规范使用命令式语言给出(即参考实现),但参考实现并不关注效率,直接使用会非常低效。
这有两个副作用。首先这样做有过度规定的趋势。第二,许多实现者直接复制规定里的代码,如果代码只是为了说明规范但没有注意效率的话就会产生问题。正如 Clark 指出的,实现者可以自由地改变参考实现,只要这两种实现具有相同的外部效果。事实上,可能还有其他结构化,且既高效又模块化的实现方式。
相当于一个 API 接口只需要提供接口参数和返回值,其内部实现自行确定即可。
P9 & P10:传递暗示
中科大课件里翻译是线索
P9 是在模块接口中传递暗示。暗示是从客户端传向服务端的信息,如果暗示正确,它可以避免服务端的大代价开销。两个关键的短语是传递和如果正确。通过在请求中传递暗示,服务端可以避免访问缓存中的关联查询。例如,暗示可以用来为接收方状态处理提供直接索引。另外,与缓存不同,暗示并不保证是正确的,因此必须与其他可证实的正确信息进行核对。如果暗示在大多数情况下是正确的,那么就会提高性能。
暗示的这一定义有一种变体,在这种变体中传递的信息被保证是正确的,因此不需要检查。由于没有一个既定的术语,我们将把这种信息称为提示。提示更难使用,因为需要确保提示的正确性。
一个例子是 Alto File System,每个磁盘块保存下一个磁盘块的指针。但是这个指针只用于暗示,如果这个指针是错的,就会重构信息。错误的暗示不会对系统正确性造成损害,只会导致性能降级。
P10 是在协议头中传递暗示。对于分布式系统,对 P9 的逻辑扩展是在消息头中传递暗示。因为本书是针对分布式系统的,所以在此单列一个原则。
一个例子是在激活消息中携带中断处理函数的地址来加速调度。另一个例子是标签交换,每个包除了带目的地址之外还携带附加索引,方便快速查找目的地址。这个标签只用作暗示,因为标签一致性无法保证,包可能被路由到错误的目的地,所以必须要检查。
这里的标签交换并不是 MPLS 的那个交换,而是一种在路由表里找目的地址的暗示。工作方式就是顺序找这些暗示下标,如果正好命中了,就不用上 Trie 上爬。但是这种暗示的例子感觉太老了,现在有在用吗?
中科大课件补充了一个 RDMA 的例子:接收端应用将准备接收数据的缓冲区地址发送给发送端应用;发送端将缓冲区地址封装在数据包中;接收端网卡将数据直接写到指定的缓冲区中,避免 CPU 参与和数据拷贝。
加速例程
之前的原则是利用系统结构,下面介绍的是单独考虑的加快系统例程的原则。
P11:优化预期情形
虽然系统可以表现出一系列的行为,但这些行为往往属于一个较小的集合,称为「预期情形」。比如设计得好的系统应该大部分应该在无故障和无异常的情况下运行。第二个例子是程序如果大部分时间都访问一个很小的内存位置集合的话,那么这个程序就有空间局部性。因此让这些共同行为高效是值得的,即使做出了异常行为代价更高。
比如说某个问题在随机数据的情况下有易于实现的低复杂度算法,但是存在不是随机的数据复杂度更高。同时有难以实现的,但是更稳定的复杂度稍高的算法。某个系统 99% 的情况下都接收随机数据,那么此时应实现易于实现的算法。因为随机是预期情形。
诸如优化预期情况这样的启发式方法往往不能让理论家满意,他们(自然)更喜欢那些利益可以在平均或最坏情况下被精确量化的机制。在为这种启发式方法辩护时,请注意,现有的每台计算机都至少在一秒钟内对预期情况进行了一百万次优化。
指分支预测。打竞赛的选手应该更倾向于复杂度更稳定的,即使很难实现,维护起来也很难。
例如,使用分页,一次访存指令可能需要最差四次内存引用(从内存读指令,读一级页表,读二级页表,从内存取值)。然而,使用缓存可以把这个次数降到 0。这也是 P11a 中提到的。
另一个例子是使用 TCP 头部预测:如果假设下一个到来的包和上一个包十分相关(比如就是上一个包的下一个),那么包处理代价就会大幅下降,不需异常处理。
注意确定常见情形主要依靠设计人员的直觉,这种直觉随时间改变可能出现错误。
中科大课件补充了常见情形也可以通过测量工具来发现。但是首先它应该是可测量的。
P12:增加或利用状态来提速
如果某个操作代价很大,考虑维护一个附加且冗余的状态来加速这个操作。例如,Charlie 跟踪忙的餐桌来优化服务员配置。这并不是绝对需要的,因为它可以在需要时在餐馆里走一圈来计算这个配置。
在数据库中,一个经典的例子是使用二级索引。除了主键索引之外,还可以在查询多的列上放索引。但要注意,维护额外的状态潜在地意味着每当发生变化时,需要修改这个状态。
然而有些时候不一定要增加状态,而是利用已有状态。我们称之为 P12a:增量计算。
当一个新顾客进来或离开时,Charlie 就会在记录服务员配置的板子上加减。第二个例子就是编译器中的强度削减(P4c),从上一次循环得到的值增量计算下一次循环的值,而不是用乘法直接绝对计算。在网络中增量计算的例子有 IP 校验和的增量计算。
P13:优化自由度
意识到在自己控制下的变量以及用于确定表现良好的评估标准将是有帮助的。然后,这个局面就变成了优化这些变量以使收益最大化。例如,Charlie 先是把空闲的服务员分配到每个餐桌上,但他意识到他可以通过把每个服务员分配到一组连续的餐桌上来提高服务员的效率。
也就是说我们不必拘泥于定式,而是分析目的以达到更高的性能。
类似的,编译器使用染色算法来分配寄存器。网络中的例子是在 IP 查询算法中使用多 bit Trie 树。这里的变量是 Trie 树上节点使用的位数可变,取决于 Trie 上的路径条数。每个节点使用的位数可以用 DP 优化,以达到最小的内存使用。
有点类似于 Trie 上节点合并。中科大课件中给的例子是 TCAM 的例子。
P14:针对有限规模问题使用特殊技术
当处理小规模问题,如中等大小的整数的问题时,通常用桶排,数组查找和 bitmap 等等的方法,而不是用通用排序或搜索算法。
为了将虚拟地址转化为物理地址,处理器首先尝试从 TLB 读缓存。如果它失败了,处理器就必须去读页表。地址位的一个前缀直接用于页表索引。页表查询避免了使用哈希表或者二分搜索,但是它需要一个很大的页表空间。网络中的例子如时间轮,使用环状数组实现了一个确定计时范围的算法。
P15:使用算法技术构造高效的数据结构
即使在有主要瓶颈的地方,如虚拟地址转换,系统设计者也会通过传递暗示、使用缓存和执行查表等方式来调节对聪明算法的需求。因此系统主设计师会和一位热心的理论家说:「我不使用算法,孩子。」
本书并没有采取这种有点反智的立场。相反,在上下文中我们认为,高效的算法可以极大地提高系统性能。事实上,本书将用相当大的篇幅来描述这些例子。然而,「我不使用算法」的说法也有其真实的内核。在许多情况下,在任何算法问题成为瓶颈之前,需要应用原则 P1 到 P14。
设计算法是最后的方法,首先设计算法本身难度很大,其次维护成本也更高,在产品迭代的过程中出现算法输入条件不适用,就需要重新设计算法。先从外部着手再向内解决是好的。
算法方法包括使用标准的数据结构以及一般的算法技术,如分治和随机化。算法可能随着系统结构和技术的变化而失效,真正的技术突破来自算法思维的运用,而不仅仅只是重用已有的算法。
第四节 设计 vs 实现原则
我们已经列出了本书中使用的原则,但还需要三点说明。第一,有意识地使用一般原则并不会消除创造力和努力,反而会更有效地引导它们。第二,这个原则清单必然是不完整的,可能可以用不同的方式进行分类,但这是一个很好的开始。
第三,说明系统设计和实现原则的区别很重要。系统设计者已经阐明了系统设计的原则。设计原则包括,例如,使用层次结构和聚合来进行扩展(例如,IP 前缀),增加一个层次的指示来增加灵活性(例如,从域名到 IP 地址的映射允许 DNS 服务器之间进行负载均衡),以及资源的虚拟化来增加用户的生产力(例如,虚拟内存)。
在 Lampson 的 Upcall 的论文和 Keshav 的 An Engineering Approach to Computer Networking: ATM Networks, the Internet, and the Telephone Network 的书中均有对设计原则的很好汇编。除了设计原则,两人都包含了一些实现原则(比如使用暗示和优化预期情形)。相反地,本书假设很多网络设计都是给定的,所以我们关注于高效的协议实现原则。
第五节 需要注意的问题
Performance problems cannot be solved only through the use of Zen meditation. –Paraphrased from Jeff Mogul, a computer scientist at HP Labs
性能问题不能只靠冥想解决。
最好的原则必须与理解重要指标的智慧相平衡,与确定瓶颈的分析相平衡,与确认变化确实是改进的实验测量相平衡。我们从两个案例研究开始,来说明谨慎的必要性。
中科大课件里是这样描述的:在运用原则前,必须理解重要的性能指标,确定系统瓶颈。在完成改进后,必须通过实验来验证效果。
案例一:减少网页下载时间
下图展示了一个 Web 客户端获取包含图片的 Web 网页的过程,它必须发送一个 GET 请求来获取网页。如果这个网页中有内嵌图片,那么客户端必须再发送一个分开的请求来获取图片以展示。这样就有一个十分自然的使用原则 P1(消除明显的浪费)的思路,为什么 Web 服务器不能自动下发图片,而是非得等客户端请求这个图片呢?这样网页下载时间就会至少下降 0.5RTT。
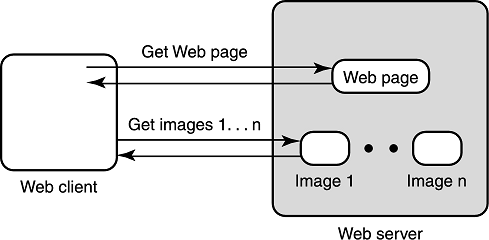
为了验证我们的猜想,我们修改了服务器软件来完成这个任务,然后测量修改后的性能。出乎我们意料的是,只有少数的延迟有改进。
使用 tcpdump 等分析工具进行分析,我们发现了两个原因:
- 与 TCP 交互:Web 传输使用 TCP。为了避免拥塞,TCP 使用慢启动机制,因为 TCP 要等待 ACK 才能增加速率,等待对图片的附加请求并不会增加延迟。
- 与客户端缓存交互:许多客户端已经缓存了通用的图片,比如
.gif图片。如果客户端已经下载,服务端还推一样的图片,这就浪费了带宽,这样做就是多余的。
在这个案例中我们能得到的教训是,改进系统的一部分是难的,因为这部分系统会与系统其他部分交互。
中科大课件还补充了实验验证在此十分重要。
案例二:加速基于特征的入侵检测
第二个例子是入侵检测系统,比如 Snort,它可以查找包 payload
中有攻击特征的可疑字符串。一个例子是字符串
perl.exe,它会执行 Perl 的解释器来在 Web
服务器上进行任意代码执行。对于每个规则,都用一个字符串表示,Snort 使用
Boyer-Moore 算法来进行字符串匹配。最差情况下可能出现一个包匹配到了 310
个规则。使用 gprof 简单测量性能就会发现 Snort 在字符串搜索上产生了 30%
的负载。
十分显然可以如下使用 P1 原则:使用一个整体的搜索算法来匹配所有规则,而不是分别搜索每个规则。可以修改 BM 算法来实现这个功能。新算法用一个库来实现,对于 Snort 的整个规则库,新算法比旧算法快 50 倍。不幸的是,当这个库集成到 Snort 里进行现网测试时,我们发现性能几乎没有提升。我们找到了如下两条原因:
- 多串匹配并不是瓶颈:对于给定的一条流,只有很少的包匹配到了多条规则。当我们换用只有 Web 流量(即只有目的端口为 80 的流量)时,性能提升很明显。
- 缓存效应:多串匹配搜索算法需要如 Trie 树的数据结构,当规则增加时数据结构会变大。最简单的方式是把这些规则都塞到一个 Trie 上,但当树大小超过 100 时,缓存就放不下这棵树了,这样性能就会下降。因此系统需要重新使用更小的规则集合实现这个算法来配合硬件(P4)。
在这个案例中我们能得到的教训是我们假设的改进其实并没有针对瓶颈,并且如果和系统的其它部分产生相互作用,可能达不到预期的效果。
八个需要注意的问题
针对这两个案例,有如下八个需要注意的问题,来警告读者不要不谨慎地使用这些原则。
Q1:提升性能是否是值得的
如果一个人去卖这套系统,那么性能是主要卖点吗?对性能提升感兴趣的人可能会这么觉得,但是系统的其他方面,如易用性,功能性和鲁棒性可能是更重要的。比如,一个网络管理产品的用户更关心功能而不是性能。因此,在给定限定的资源和实现复杂度的情况下,我们可以选择将优化工作推迟到需要时进行。即使性能是重要的,那么哪个性能度量(如吞吐量,内存)是重要的?
在其他条件相同的情况下,简单的是最好的。简单的系统容易理解,调试和维护。另一方面,对于简单的定义也随着科技和之间的发展而变化。对于大的性能提升,一定程度的复杂性是值得的。例如,很多年前,诸如 MPEG 等图像压缩算法被认为太过复杂,在当时的软硬件条件下不能实现。然而,随着芯片密度的提升,许多 MPEG 芯片已经被推向市场。
没解决问题之前先要考虑这个问题是否有价值解决,这是好的。
Q2:这是否是真正的瓶颈
二八定律暗示了大部分性能问题来自优化系统的一小部分。一个简单的开始方法是确定我们希望优化的性能指标的关键瓶颈。实现它的一种方式是使用 profiling 工具,就像案例二所做的一样。
对于需要解决的问题,我们应该确定这个问题的实质出现在哪儿,也就是根本问题是什么。
Q3:这个改变对系统其他部分有什么影响
一个简单的改变可能会加速系统的一部分,但可能会对系统的其他部分产生复杂和不可预见的影响。这个在案例一中有所体现。一次性能升级可能需要考虑很多交互。
一个能够提高性能、但会带来太多相互作用的修改,需要重新考虑。
Q4:初步的分析是否表明会有重大改进
在做完整实现前,首先可以对能获得的改进进行分析。标准的复杂度分析是有用的。然而,当每个纳秒都很关键时,常数因子就很重要。对于软硬件,因为访存是一个瓶颈,一个合理的首轮评估可以评估访存次数。
例如,假设分析表明在路由器中地址查询是瓶颈(例如,因为有快速交换机让数据传输不是瓶颈)。假设标准算法平均需要 15 次访存而新算法只需要最差 3 次访存。这就表明了有 5 倍的性能提升,实现它就十分有效。
应在实现前评估收益。
Q5:添加定制硬件是否值得
随着通用处理器性价比的不断提高,在软件中实现算法并利用性价比曲线是很有吸引力的。因此如果我们考虑需要设计一年的定制硬件,获得的性价比也只有 2 时,这就不值得了。另一方面,使用有效的设计工具,硬件设计时间在缩短。批量制造也可以使定制设计的芯片的成本极小(与通用处理器相比)。在竞争激烈的市场中,即使是一小段时间,如一年,拥有优势也是很有吸引力的。这导致公司越来越多地将网络功能置于芯片中。
现如今 FPGA 的出现又使设计的成本降低了。需要考虑软硬件的 trade-off。
Q6:是否能够避免协议变化
近年来,已经有一些提案谴责某些协议是低效的,并提出了为性能设计的替代协议。比如 80 年代,传输协议 TCP 被认为是「慢」的,然后出现了一种针对硬件设计的协议 XTP,这刺激了加速 TCP 的研究,最终 Van Jacobson 在标准 BSD 中对 TCP 进行了快速实现。最近,关于改变协议(如标签和流量转换)以减少对 IP 查询的需求的建议刺激了对快速 IP 查询的研究。
中科大课件:如果仅是为了提高性能而修改协议,我们不妨去研究如何高效地实现协议。
Q7:原型系统是否证实了最初的设想
一旦我们成功回答了上述问题,搭建一个原型系统或者模拟环境来实际测试性能改进是不是真的也是一个好主意。这是因为我们正在面对的是复杂系统,在最初的分析中不会把生产环境中的方方面面都考虑到。比如案例一中的例子,我们只有实地测量了之后才知道延迟降低不明显。
主要问题是找到一组标准的基线来比较标准和新实现。例如,在通用系统中,对浮点数性能(Whetstone)或者数据库性能(debit-credit)都有标准基线。如果一个人声称使用差分编码减小了 Web 传输时延,用哪组网页可以做到一个合理的基线来证明他的方法确实有提升?如果一个人声称找到了一个小存储量的 IP 查询方案,应该使用哪个基线数据库来证实他说的?
Q8:性能提升是否会随着环境改变而消失
可悲的是,即使实现了原型,并且基准测试显示性能改进接近于最初的预测,工作也没有完全结束。难点在于性能提升可能只在特定使用的(可能变化的)平台上,并且可能利用了某些基线测试集的性质(可能没有完全反映生产环境的情况)。这些改进可能仍然是值得的,但某种形式的敏感性分析对未来仍然有用。
比如,Van Jacobson 对 BSD
的网络代码进行了一次大优化,使普通工作站能够跑满 100Mbps 的
FDDI(光纤分布式数据接口)环。这个优化(在第九章还会深入研究)假设在正常情况下,下一个数据包与上一个数据包
第六节 总结
至此,我们已经完全介绍了 15 个实现原则。就像在下棋之前,国际象棋策略是枯燥的一样,没有具体的例子,实施原则也是没有生命力的。这些原则都是从实践中总结出来的,读者仍需自己在实践中总结和体会。
第七节 练习
鸽了