文章包含哈尔滨工业大学高级算法设计与分析课程作业、实验和大作业的个人解析。
四个实验可以参考这里 。大作业可以选分布式一致性
hash ,问题不大,资料也比较多(毕竟上课和面试八股里都有),可以参考
Stanford CS 168 的
Lecture
1 ,讲义很清楚,里面有一致性 hash 的出处论文。PPT
自己做吧,还得录音,哈哈。
原来以为这个研究会发 SOSP 或者 SIGCOMM 这种,但是居然发的是理论的
STOC。
最 nb 的是作业要手写,哈哈,给助教磕一个吧。为了整这堆东西,Skyplane
论文看得磕磕巴巴,DuVisor
的博客来不及写,网络算法学也好几周没看,认真整这玩意真的就输了。
第一次作业
一、证明:
设
令
由于
所以
从而
二、用迭代法 解递归方程:
则有
三、求解递归式:
四、求解递归式:
根据 Akra–Bazzi 定理
即
五、求解递归式:
根据 Master 定理,
六、根据表达式
a. 输入实数
a. 递归伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 Pow(a, n) if n = 0 then return 1 if n = 1 then return a result := Pow(a, n / 2) if n mod 2 = 0 then return result * result else return a * result * result endif
可以写出递归式
b. 递归伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 PowMatrix(A, n) if n = 0 then return I if n = 1 then return A result := PowMatrix(A, n / 2) if n mod 2 = 0 then return result * result else return A * result * result endif
可以写出递归式
七、给定平面上
首先考虑对于一个「友谊点对」,一定存在一个以这个点对为对角线的矩形包含这个点对。对于这个缩小的矩形退化为一条线段的情况,那么我们可以给长(或宽)加上一个无穷小量保证其为一个矩形而满足题目要求。因此问题可以规约到统计满足下列条件的点对数量:
以这个点对为对角线的矩形内部或边界上(或退化成的线段上)没有其他点。
首先将所有点按
计算这些点中
用水平线
计算点对中两点分别在上半部分和下半部分的时候对答案的贡献;
递归地计算上半部分和下半部分分别对答案的贡献。
对于边界情况,如果目前的点集为空集或只有一个点,则直接返回,如果只有两个点,则对答案有贡献
对于计算贡献部分,由于点对中两点分别位于上半部分和下半部分,所以仅需考虑上半部分的点作为左上或右上,下半部分的点作为左下或右下的情况。
考虑上下两部分
所以,对于枚举到的点
对于下半部分,仍然按从左到右的顺序考虑,如果有
之后,对于上层枚举到
综上,选定上半部分的某一个点为右上角的情况对答案的贡献已经处理完毕。选定上半部分的某一个点为左上角的情况与其类似,我们只需要将所有点沿
至此,第 3 步已经处理完毕。
考虑时间复杂度,我们按照
我们在考虑上半部分时,每个点会被枚举一次,并且由于出栈后的点不会在入栈,因此出入栈最多一次,在考虑下半部分时,同样每个点被枚举一次,出入栈最多一次。所以在处理上半部分的区间和下半部分对答案有贡献的点的时间复杂度为
原题为 JOISC 2014
稻草人 ,代码可以参考这里 。只需要把点按
八、输入含有
考虑对树进行点分治,定义一棵树的重心为如果以这个点为根,没有任何点的子树大小超过
考虑先找到一棵树的重心,将其分为一些子树。那么所有点对之间的路径就可以分为如下两种情况:
点对之间路径完全在一个子树中;
两点分别位于两不同子树(或其中一点为重心),易知这条路径一定过重心;
考虑情况
1,为原问题的一个子问题,首先找出其子树的重心,然后递归地调用该算法即可。对于找出一棵树的重心,可以先统计出这棵子树中每个节点以它为根时每棵子树大小,之后根据定义找到重心。我们可以类似前缀和地统计,对于「向上」的子树大小,为整棵树的大小减去以这个节点为根「向下」的所有子树大小之和。因此统计中树上节点全部被统计一次,时间复杂度为
考虑情况 2,由于需要统计
实际上两个问题性质相同,考虑如何统计
考虑对
分析上述统计过程的时间复杂度,首先排序带来了
由于一条路径要么过重心,要么不过重心。在问题分解时情况已经考虑完全,子问题之间没有重复,因此算法正确性易得。
由于重心的子树没有任何点子树大小超过
点分治入门题,可以在坟 里看。
九、给定平面上
考虑使用与求平面最近点对类似的算法。假设目前要处理的点集
如果
否则,计算
令
再基于同样考虑,选定了一个点
对于这部分复杂度,和最近点对同样采用画格法考虑,由于对于每一个
综上,我们每步将问题分解成了两个规模为
原题来自 BJWC 2011
最小三角形 ,顺便重写了一下严格 这里 。注意做比较的时候距离是有平方的,水平和竖直方向上的距离求完坐标差之后要平方。
十、设
考虑归并排序的同时统计逆序对数量。首先将序列从中间分为两部分。即,对于序列
递归统计两个部分内部的逆序对数量并归并排序后,将左右两部分有序序列归并并统计左边对右边逆序对的影响。考虑二路归并时左边出现了一个大于右边的数,这就证明出现了逆序对。每次后段首元素被作为当前最小值取出时,前段所有剩余元素都会与这个元素形成一个逆序对,因此前段剩余元素个数即是后端首元素对逆序对的贡献。因此,分割后归并的同时统计逆序对数量即可。
对于分割部分,我们分割成了两个互不相交的子问题,二路归并中,所有元素均被访问一次,统计逆序对仅需要计算前段数组长度与现在前段的指针位置的差值,时间复杂度为
综上,可以写出递归式
第二次作业
动态规划
一、设你要爬
1. 证明该问题的优化子结构,说明子问题的重叠性。
1. 本问题为一计数问题而非优化问题。令现在我们位于第
2. 由 1 可知,状态转移方程为:
1 2 3 4 5 CountStep(n) f[1] = 1, f[2] = 2 for i = 3 to n do f[i] = f[i - 1] + f[i - 2] return f[n]
3. 由状态转移方程,共有
实际上
二、考虑三个字符串
1. 寻找反例
1. 考虑
2. 类似 LCS 在两个串情况下的求法,优化子结构如下:设
如果
如果不满足
如果不满足
如果不满足
对于 (1),设
对于 (2),由于
对于 (3),(4),证明同 (2)。
因此令
伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 LCS-length(X, Y, Z) n = length(X), m = length(Y), l = length(Z) for i = 0 to n do for j = 0 to m do for k = 0 to l do f[i, j, k] = 0 for i = 1 to n do for j = 1 to m do for k = 1 to l do if X[i] = Y[j] and Y[j] = Z[k] then f[i, j, k] = f[i - 1, j - 1, k - 1] + 1 B[i, j, k] = 1 else if f[i - 1, j, k] is max of {f[i - 1, j, k], f[i, j - 1, k], f[i, j, k - 1]} then f[i, j, k] = f[i - 1, j, k] B[i, j, k] = 2 else if f[i, j - 1, k] is max of {f[i - 1, j, k], f[i, j - 1, k], f[i, j, k - 1]} then f[i, j, k] = f[i, j - 1, k] B[i, j, k] = 3 else f[i, j, k] = f[i, j, k - 1] B[i, j, k] = 4 return f and B Print-LCS(B, X, i, j, k) if i = 0 or j = 0 or k = 0 then return if B[i, j, k] = 1 then Print-LCS(B, X, i - 1, j - 1, k - 1) Print(X[i]) else if B[i, j, k] = 2 then Print-LCS(B, X, i - 1, j, k) else if B[i, j, k] = 3 then Print-LCS(B, X, i, j - 1, k) else Print-LCS(B, X, i, j, k - 1) return
对于求最长公共子序列长度,可知有
对于输出最长公共子序列,时间复杂度为
三、给定一个
设
伪代码为
1 2 3 4 5 6 7 8 9 MinSum(n, m) for i = 1 to n do f[i, 1] = f[i - 1, 1] + a[i, 1] for i = 1 to m do f[1, i] = f[1, i - 1] + a[1, i] for i = 2 to n do for j = 2 to m do f[i, j] = min(f[i, j - 1], f[i - 1, j]) + a[i, j] return f[n, m]
可知时间复杂度为
四、给定一个整数序列
1. 用简明的语言表述这个问题的优化子结构。
1. 若计算
2. 令
其中
3. 伪代码如下
1 2 3 4 5 6 7 8 9 10 11 Merge(n) for i = 1 to n do f[i, i] = 0 s[i] = s[i - 1] + a[i] for l = 2 to n do for i = 1 to n - l + 1 do j = i + l - 1 f[i, j] = 0 for k = i to j - 1 do f[i, j] = max{f[i, j], f[i, k] + f[k + 1, j] + s[j] - s[i - 1]} return f[1, n]
根据伪代码,可知此算法时间复杂度为
五、输入凸
设
则
设
其中
伪代码如下
1 2 3 4 5 6 7 8 9 10 MinC(n) for i = 0 to n do f[i, i] = 0 for l = 2 to n do for i = 2 to n - l + 1 do j = i + l - 1 f[i, j] = infty for k = i to j - 1 do f[i, j] = min{f[i, j], f[i, k] + f[k + 1, j] + C(a[i - 1], a[j], a[k])} return f[1, n]
由伪代码可知,时间复杂度为
贪心算法
一、一棵树,结点个数为
1. 给出贪心策峈;
1. 考虑等价问题:求一个点的排列
由排序不等式,考虑让权值大的点排在前面,而在选这个权值最大的点前要先选父节点。考虑一个合法的排列
化简后有
可以解释为:已经预合并了两段点
2.
贪心选择性:第一次一定选择权值最大的点与父亲合并。如果不是,设权值最大的节点为
交换
由于
优化子结构:考虑已预合并的两端要合并起来,方法同 (1) 中说明。
3. 伪代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 Color(n) S = {}, ans = 0 for i = 1 to n do Insert(S, c[i]) while S is not empty do x = Extract-max(S) f = Tree-top(x) Union(x, f) Delete(S, f) ans += c[x] * siz[f] c[f] += c[x], siz[f] += siz[x] Insert(S, c[f] / siz[f]) return ans
首先将这些点插入平衡树中,时间复杂度为
对于这棵平衡树,每次操作都减少一个元素,合并两预合并段的时间复杂度需要先进行平衡树上查询,再进行并查集的查询和合并,然后进行一次平衡树的权值修改(用一次删除和一次插入表示),时间复杂度为
实际上为 POJ
2054 ,代码在这里
二、给定两个大小为
每次选择两集合中最大的
伪代码如下
1 2 3 4 5 6 MaxF(A, B) n = Size(A) sort(A), sort(B) for i = 1 to n do f[a[i]] = b[i] return f
首先我们分别对
正确性证明如下。
1. 贪心选择性:对排序后(从大到小)的
假设优化解中不存在
而交换这两个映射,代价为
考虑
由以上,做一次交换不会使代价变劣,原假设不成立。因此优化解中存在
2. 优化子结构:只需证
综上,上述贪心算法的正确性得证。
三、给定平面点集
首先由于要输出集合,因此最差情况下不可避免遍历
至于贪心算法,本题可转化为:平面上目前已有点集
怎么改题意之后想都是一个计数问题,比如找左下方没有点的最大子集什么的,那直接二维偏序就好了。总感觉我和出题人总有一个题意挂了。
四、一个 DNA 序列
1. 给出贪心策略;
1.
按右端点从小到大排序后枚举每个区间,先将第一个区间加入几何,然后只要当前区间左端点在集合中最后一个区间的右端点右边,就选择这个区间加入集合。
2. 贪心选择性:设
优化子结构:设
3. 伪代码
1 2 3 4 5 6 7 8 9 IntervalSelect(P, Q) sort(P, Q) S = {1} j = 1 for i = 2 to n do if P[i] > Q[j] then Append(S, i) j = i return S
首先对线段按照右端点从小到大排序,时间复杂度为
五、某工厂收到
首先排除一定不能完成的订单,即
贪心选择性:考虑
优化子结构:设
伪代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 MinReject(n, a, b) sort(a, b) sum_a = IntervalTree(n) min_b_sa = IntervalTree(n) accept = [] for i = 1 to n do if b[i] > a[i] continue if Sum(sum_a, 1, b[i]) + a[i] > b[i] then continue if Min(min_b_sa, b[i], INF) < a[i] then continue sum_a[b[i]] += a[i] min_b_sa[b[i] .. INF] -= a[i] Insert(accept, (a[i], b[i])) return accept
由伪代码,排序的复杂度为
之后遍历每个任务,首先检查目前的任务是否满足可以在截止时间的时候完成,通过第一棵线段树查一下前缀和即可,然后检查插入这个任务后是否会使之前插入的任务不能完成,即第二棵线段树以
每次线段树上查询和修改的时间复杂度均为
实际上为 「JSOI2007」建筑抢修 ,代码在这里 。当然
std 应该是按
六、有
1. 给出贪心策略;
1. 每次选择重量最小的两堆石子
2.
贪心选择性:考虑合并过程中形成的二叉树,若第一次合并未选择重量最小的两个石子,而将其中一个换为
最优子结构:设
3. 伪代码如下
1 2 3 4 5 6 7 8 MergeStone(W) n = |W|, Q <- W 且 Q 是小顶堆, ans = 0 for i = 1 to n - 1 do x = Extract-min(Q) y = Extract-min(Q) ans += x + y Insert(Q, x + y) return ans
首先构建小顶堆的复杂度为
第三次作业
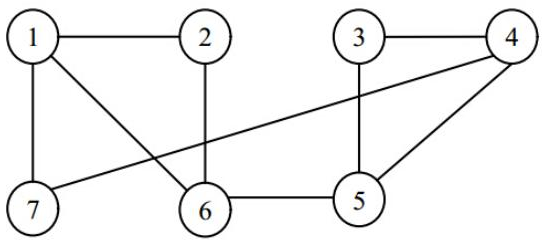
一、在下图中考虑哈密顿环问题。将问题的解空间表示成树,并分别利用深度优先搜索和广度优先搜索判定该图是否存在哈密顿环。
首先要画搜索树,但是搜索树太大了,自己画吧。
使用深度优先搜索,伪代码如下:
1 2 3 4 5 6 7 DFS(G) 1. 构造由 {1} 组成的单元素栈 S 2. If Top(S) 的长度为 8 Then 输出 Top(S),停止 3. Else T = Top(S), Pop(S) 4, 将每个与 T 的最后一个元素相连,且不在 T 中的元素(除 1 以外)加入 T,压入 S 5. Goto 2 6. If S 空 Then 无解
使用广度有限搜索伪代码如下:
1 2 3 4 5 6 7 BFS(G) 1. 构造由 {1} 组成的单元素队列 Q 2. If Q 的首元素长度为 8 Then 输出首元素,停止 3. Else T = Q 的首元素, 弹出 T 4. 将每个与 T 的最后一个元素相连,且不在 T 中的元素(除 1 以外)加入 T,加入 Q 5. Goto 2 6. If Q 空 Then 无解
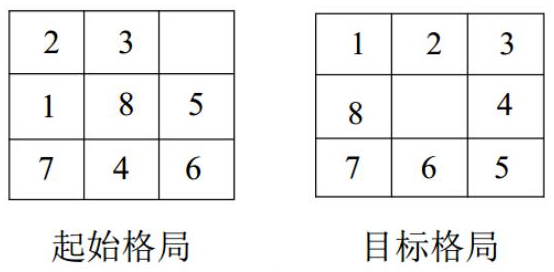
二、考虑
8-魔方问题。分别用爬山法,最佳优先方法判定上图所示的初始格局能够通过一系列操作转换成目标格局,将搜索过程的主要步骤书写清楚。
话说这玩意不叫八数码吗……
使用爬山法,令启发式测度函数
1 2 3 4 5 1. 构造由初始局面组成的单元素栈 S 2. If Top(S) 是目标局面 Then 停止 3. Pop(S) 4. 对于 Top(S) 的所有可能移动,按新局面 f(n) 从大到小的顺序压入 S 5. If S 空 Then 无解 Else goto 2
使用最佳优先方法,根据评价函数
1 2 3 4 1. 使用评价函数构造小根堆 H,将初始局面插入 H 中 2. If H 的根 r 是目标局面 Then 停止 3. 从 H 中删除 r,将 r 移动后所有可能的局面插入 H 4. If H 空 Then 无解 Else goto 2
三、精确描述求解 8-魔方问题的 A* 算法,在习题 2
给出了起始格局和目标格局上给出 算法操作的主要步骤。
1. 设计
1. 令
2. 过程如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 2 3 0 1 8 5 7 4 6 1. 2 0 3 2 3 5 1 8 5 g(n) = 1 1 8 0 g(n) = 1 7 4 6 h(n) = 7 7 4 6 h(n) = 10 2. 0 2 3 2 8 3 1 8 5 g(n) = 2 1 0 5 g(n) = 2 7 4 6 h(n) = 6 7 4 6 h(n) = 8 3. 1 2 3 0 8 5 g(n) = 3 7 4 6 h(n) = 5 4. 1 2 3 1 2 3 8 0 5 g(n) = 4 7 8 5 g(n) = 4 7 4 6 h(n) = 4 0 4 6 h(n) = 6 5. 1 2 3 1 2 3 8 4 5 g(n) = 5 8 5 0 g(n) = 5 7 0 6 h(n) = 3 7 4 6 h(n) = 5 6. 1 2 3 1 2 3 8 4 5 g(n) = 6 8 4 5 g(n) = 6 7 6 0 h(n) = 2 0 7 6 h(n) = 4 7. 1 2 3 8 4 0 g(n) = 7 7 6 5 h(n) = 1 8. 1 2 3 8 0 4 g(n) = 8 7 6 5 h(n) = 0
四、分别使用深度优先法和分支限界法求解子集和问题的如下实例。
输入:集合
使用深度优先搜索伪代码如下:
1 2 3 4 5 1. 构造由空集组成的单元素栈 S 2. If Top(S) 的集合元素和为 K Then 停止 3. 令 C = Top(S), Pop(S) 4. 对于每个不在 C 中的元素 x,C <- C ∪ {x},将 C 压入 S 5. If S 空 Then 无解 Else goto 2
使用分支界限法可以缩小解空间的范围,伪代码如下:
1 2 3 4 5 6 1. 构造由空集组成的单元素栈 S 2. If Top(S) 的集合元素和为 K Then 停止 3. 令 C = Top(S), Pop(S) 4. 对于每个不在 C 中的元素 x,如果加入 C 后集合元素和仍 小于等于 K,则 C <- C ∪ {x},将 C 压入 S 5. If S 空 Then 无解 Else goto 2
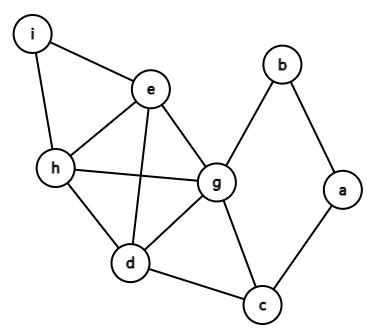
五、利用搜索求下图的最大完全子图(团),要求写出计算过程。
抄一下 Bron–Kerbosch
Algorithm 。
第四次作业
随机算法
一、一个木桶里有
令
化简可得
由已知,
二、传送带上有若干产品,一个质量检测员在传送带某一检测点工作,如果他今天要检测
1.
请帮他设计一个检测算法,使得整条传送带上的所有产品被选中的概率相同。
1. 首先取走传送带上前
等到所有产品都通过后,待检区内的产品就是要检测的产品。
2. 要证:对于传送带上前
使用归纳法。当
当第
Reservoir
sampling - Wikipedia
近似算法
一、试着修改集合覆盖算法求解加权集合覆盖问题,并分析它的近似比。
可以参考 Encyclopedia of
Algorithms 和 UW
CSE 525 ,写得都挺好的,翻译一下就好了。
二、考虑下述场景。给定一个城市集合以及城市之间的距离,从中需要选出
输入:平面上的点集
下面是一个求解 K-center
问题的基于贪心策略的近似算法,请证明它的近似比是
可以参考 Metric k-center -
Wikipedia 和 Geometric Approximation
Algorithms Chap. 4.2 。
书里的反证法很巧妙。
在线算法
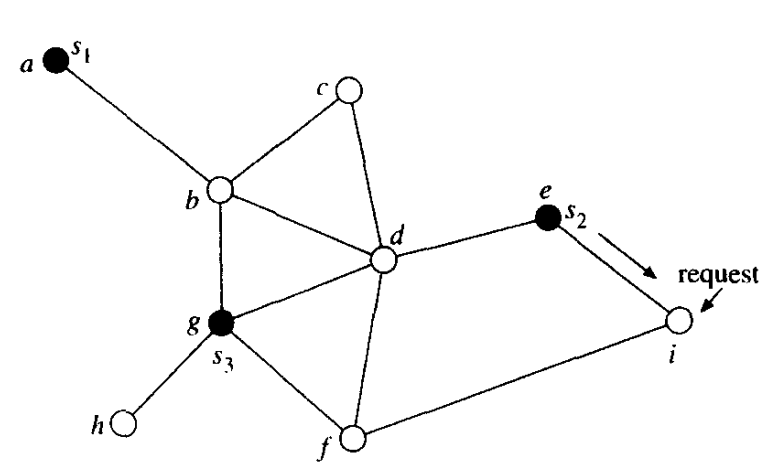
一、已知有
是一个 k-server
problem ,题面就是 Introduction to the Design and Analysis of
Algorithms 书里 12.2 节的例子,书在 Z-lib 能下到,注意作者是 R. C. T.
Lee,并且书也挺老了,别下错了。但是看证明过程还是看 On-line Computation
and Competitive Analysis 10.4 节的,写得很明白。
原论文 中要求是完全图,但是一般图也是符合三角不等式的,考虑在最短路树上走就可以了。其实也可以直接看
An Optimal On-Line Algorithm
for K Servers on Trees 这篇论文。
期末考试
考试考得贼小丑,虽然考试大部分还是作业里的,但是考前没看,哈哈。
先上来考的求时间复杂度,反正递推一下就行,一个主定理也不难。
然后是一个求哈密顿圈的分支界限搜索,要画搜索树,反正也就那么画。
然后是一个贪心,给了 LOJ
#10002 ,在考场上纠结怎么排序,笑死。
然后是一个 DP,求最大子段和,随便搞搞就行了。
随机算法考的蓄水池抽样,但是要抽连续
近似算法考的是一般图最小权覆盖的近似算法,就在 PPT
上但是我没看,近似比