Security and Performance in the Delegated User-level Virtualization 论文浅述
云计算安全课要看一篇论文并且汇报,正好前几天看知乎的 IPADS 组有这么一篇论文,还挺合适的,所以就拿来汇报了。汇报的时候 OSDI ’23 还没开,参考的论文是 arXiv 上的预印本。但是现在已经开了,所以直接根据正式版论文更新了细节,并删除了预印本部分。
看完之后大受震撼,但是由于我不是做这个方向的,描述上可能有谬误,敬请指正。
文章中图片,表格和数据全部来源于正式版论文。
论文在这里。
个人评论仍用引用表达,并且可能有失偏颇,请勿引用。
Abstract
今天主流的虚拟化系统被诸如 KVM 的内核中 hypervisor 暴露的巨大攻击面所引起的严重安全威胁困扰。为了解决这个问题,本论文提出了一种称为托管虚拟化的全新设计,它可以将 hypervisor 解耦为两个平面:用来控制 hypervisor(通常很小,逻辑固定)的 hypervisor 平面(控制面)和用来处理虚拟机请求和运行时异常虚拟机平面(数据面)。我们的研究显示,对于所有在 VM 平面威胁主机内核的 hypervisor 漏洞,托管虚拟化完全将内核中的 VM 平面卸载到可以直接和 VM 交互,而不需要退出到内核的用户空间 hypervisor 上,称为 DuVisor,DuVisor 基于一个很小的硬件扩展(481 行 Chisel 代码)。我们已经在 FireSim 上,使用开源的 RISC-V CPU 实现了这个硬件扩展,并在其上使用 Rust 语言编写了 DuVisor。评估显示 DuVisor 在可忽略的性能开销(小于 5%)下显著缩小了攻击面。
这里的控制面指内核的控制面,内核驱动只控制虚拟机的启停和一些内存溢出等严重错误,剩下 VM exit 事件都是由数据面来负责操作的。和预印本不同的是,正式版论文删除了对于性能提升的表述,我觉得也是,整个论文应该是提升的安全性,性能不明显下降就很好了。并且控制面和数据面说得更直接了,挺好的。
研究的问题
虚拟化分为三个阶段。第一阶段是如早期 IBM VM/370 的,直接把虚拟化功能实现在内核态里,实现虚拟化。第二阶段是把一些 hypervisor 函数移到内核态,利用系统调用复用操作系统功能,实现虚拟化。这种虚拟化方案仍然需要在内核态运行一些函数,比如指令仿真和内存虚拟化。
目前的虚拟化方案正处于第三阶段,即使用虚拟化硬件扩展,将一部分虚拟化函数放在硬件扩展中,以提高性能。虚拟化硬件扩展如 Intel VMX,AMD SVM 等,这些扩展通过将一些虚拟化函数移进硬件,更大规模地缩小了虚拟化中内核的参与。
这种虚拟化通常包含两个交互的组件:内核态组件和用户态 helper。比如 KVM 虚拟化就包含一个 KVM 内核模块和用户态 helper(比如 QEMU)。KVM 模块和硬件扩展与主机内核交互,用户态 helper 负责 VM 管理和 I/O 虚拟化。
但这种设计同时面临安全问题和性能问题。如下表展示了对 KVM 和 Xen 的 CVE 分析,Host 代表可能导致对主机内核攻击的漏洞。PE、DoS 和 DL 分别代表提权、拒绝服务和数据泄漏。Other 表示只攻击 VM 或者不能被利用的 CVE。LoC 表示他们的代码行数,Time Scale 表示 CVE 分析的时间跨度。
本文的主要思想是:将运行时与 VM 交互的所有 hypervisor 组件都放到用户态。
从原理来说应该是这样,因为整个 VM 都在用户态,从理论来说,与 VM 交互的组件能够获得的权限集合应该就是 VM 获得的权限集合,否则 VM 通过潜在的漏洞逃逸,理论上首先就需要通过 hypervisor,如果这里 hypervisor 的权限较大,那潜在可利用的威胁就变大了,属于扩大了攻击面。当然,这样做似乎也是回到了把所有的 hypervisor 全放在内核态里,VM 执行 VM exit 事件的时候(naive 的情况下)还需要进内核,这样性能就不好了。当然,后面有一系列操作解决了性能问题。
这样做有三个问题:
特权限制:现代硬件虚拟化扩展只能在内核态下配置,比如设置 VM 的二阶段页表。这就需要在主机内核中存在一个管理程序组件来使用这些扩展。
安全风险:简单地把所有 VM 硬件资源管理移到用户态违背了最小权限原则,并且扩大了攻击面。例如,如果允许 QEMU 修改一个 VM 的二阶段页表,它就可以访问任意物理内存页,暴露了一个显著的安全威胁。
这与上面所说的不相违背,也就是与 VM 交互的组件全在用户态和简单地把 VM 硬件资源管理移到用户态违背最小权限原则这两件事,这是两个组件
性能开销:大多数 VM exit 目前都会被内核转发到用户态来处理。这样的话,为了恢复 VM 运行,控制流必须再次返回内核,这样就导致了多余的运行时跨 ring 和不可接受的性能花费。
这一切的问题根源在于硬件虚拟化扩展和内核之间不必要的紧耦合,由于要缩小内核部分,就要将不必要在内核态的虚拟化函数挪到用户态,但是移动函数到用户态势必带来状态切换,这样又导致了性能损失。在这种情况下,安全和性能两边都无法实现令人满意的效果。
而如今,硬件又出现了新的改进,如 Intel 和 RISC-V 允许用户态进程处理物理中断,称为用户级中断。并且 RISC-V 的 Physical Memory Protection(a.k.a. PMP)技术支持在硬件层面限制一个程序能访问的内存范围。所以如何结合新的硬件改进,从根本问题入手,将硬件虚拟化扩展和内核进行解耦,开发新的虚拟化的方法以取得虚拟化安全和性能的平衡即为本研究的主要研究内容。
这篇文章出来我才知道有这么个指令集,十分震撼。
研究的目标
- 提出托管式虚拟化架构,将整个 VM 平面卸载到用户级的 DuVisor 上,并且在内核中只保留一个很小的 DV-driver,缩小攻击面。
- 设计一个轻量级硬件 DV-Ext,使得 DuVisor 可以在用户模式下为 VM 提供服务。
- 使用 RISC-V 通过最小的修改实现硬件扩展,并且用 Rust 搭建 DuVisor 原型。
- 使用周期精确的 Firesim 和一套真实世界的应用,对 AWS F1 FPGA 上的虚拟机管理程序进行评估。
研究的方法
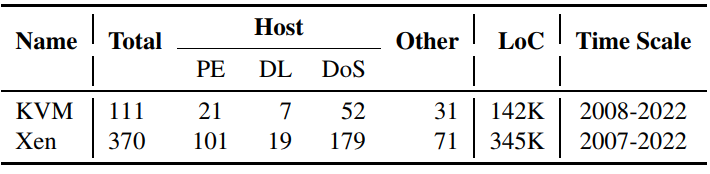
结合硬件新特性,设计托管虚拟化(delegated virtualization)。用户态 hypervisor(DuVisor)可以安全高效地在用户态控制所有虚拟化函数,DuVisor 直接利用虚拟化扩展的寄存器和指令,为敏感指令、二阶段页表缺页和 I/O 操作引起的 VM exit 事件提供服务,而不需要进入内核态。内核态驱动只负责初始化 DuVisor 和处理严重错误,一个 VM 由一个 DuVisor 进程管理,使用 PMP 技术来限制 DuVisor 所能访问的物理内存。如果 DuVisor 非法访问其他 VM 的内存,就会产生一个严重错误,交给内核处理,确保安全性。整体架构图如下图所示。
假设的威胁模型是硬件(包括 DV-Ext)实现正确,并且可信。DuVisor 的目标是防御恶意 VM 不会入侵主机内核,因此主机内核和 DV-driver 也是可信的。然而,在一个多租户云环境中,被恶意租户控制的客户 VM 可能利用 DuVisor 的漏洞去欺骗 hypervisor,因此用户态 DuVisor 进程是被主机内核认为是不可信的。侧信道攻击和相关的防御方式与 DuVisor 的设计正交,因此文章没有考虑这些攻击。
为了实现 DuVisor,研究中设计了针对 DuVisor 的硬件扩展 DV-Ext,DV-Ext 基于 RISC-V Rocket CPU 实现,复用已有的硬件特性,如虚拟化扩展(H-Ext)和用户级中断扩展(N-Ext),并添加或修改了一些寄存器指令,如下表所示。

这些寄存器分为 HU 和 HK 两类,HK 是内核态中 hypervisor
使用的寄存器,这些寄存器不会暴露给 HU 模式。HU 模式是用户态 VM
平面中使用的寄存器。这些寄存器分为两类,一类是记录 VM exit 信息的,比如
hu_er 和 hu_einfo,第二类是控制运行时
hypervisor 或 VM 行为的,比如 hypervisor 可以配置 hu_vitr
来向 vCPU 注入一个中断。
DV-Ext 提供了一个可托管的 VM exit(DVE),它可以让 VM 在 HU
模式下立刻进入 DuVisor。内核态下可以通过修改 h_deleg
寄存器来配置 DVE,HK 模式下,这个寄存器的每个位都表示一种类型的 VM
exit。比如通过设置这个寄存器,在 HK 模式下的 DV-driver
可以托管二阶段页表缺页和敏感指令错误,比如
WFI(即等待中断指令,这是为了进入节能的 stand-by CPU 状态,类似 x86 的
HLT)到 HU 模式。当 DVE 发生时,硬件会用 hu_ehb
中的地址搜索 hypervisor 的 handler。DV-Ext 还在 HU 模式下提供了
HURET 指令,在处理完 DVE 之后恢复 VM 执行,VM 入口存储在
hu_vpc 寄存器中。
因为存储二阶段页表基地址的寄存器在 VM 启动之后几乎不变,DV-Ext 不会将它暴露给 HU 模式。然而,在 HU 模式下,用户级 hypervisor 仍然可以通过把二阶段页表暴露给 HU 模式来自由更新二阶段页表。因此,页表格式和原始 HK 模式中使用的二阶段页表是一致的。因为 HU 模式在更新二阶段页表之后要刷新 TLB,所以 DV-Ext 提供了一个指令来刷新与一个特定 GPA(用户物理地址)和 VMID 关联的 TLB。
posted interrupt(不知道咋翻译……)允许 hypervisor 在不产生 VM exit 的情况下发送一个虚拟中断给一个正在运行的 vCPU。DV-Ext 支持这么做,可以直接给绕过 VM exit 给 vCPU 发中断。DV-Ext 还添加了虚拟计时器中断,它可以在不产生 VM exit 的时候被触发。
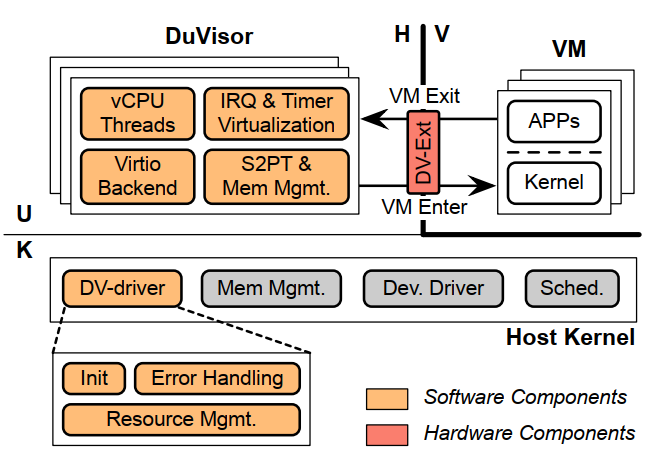
DV-Ext 在进行 VM exit 的操作流程图如下图所示。
VM exit 要么是异常导致的,要么是物理中断。所有异常导致的 VM exit 都会被发送到用户级的 DuVisor,而物理中断继续中断,直到主机内核处理。把物理中断定向给 HU 模式是不合适的,因为 HU 模式对主机内核的调度和设备管理等任务至关重要,而 HU 模式是不可信的。
对于由同步异常引起的 VE,CPU 控制流直接从虚拟机捕获到 DuVisor 的 VE
handler。然后这个 handler 根据相关 HU 模式寄存器判断异常类型。在处理完
VE 后,通过执行 HURET 恢复 VM。
当出现物理中断时,VE 被定向到 HK 模式。为了保证 DuVisor VM
的寄存器状态不被调度损坏,DV-driver
会在处理物理中断前保存现场,并且在回到 V 模式前用 SRET
指令恢复现场。实验发现这样附加的保存和恢复现场对性能的影响是极小的。
这一部分相对预印本添加了更多物理中断细节,但是总之还是那么个流程。物理中断没有太好的优化方法,为了安全还是只能进内核态来搞。当然还有一些关于 I/O 的外部物理中断,十分细碎,这个是可以绕过 VM exit 直接给 vCPU 发中断的,使用 UIPI 即可。原文这里其实又说了一遍,我没写在正文罢了。
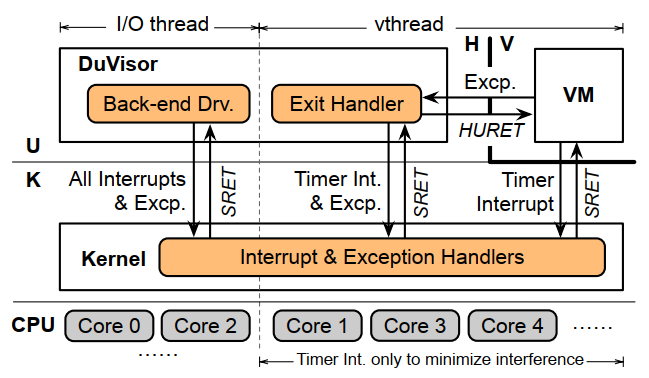
DV-Ext 在进行内存访问操作时执行过程如下图所示。
首先由虚拟机内系统内核进行用户虚拟地址到用户物理地址的转换,然后交由 DuVisor 进行用户物理地址到宿主机物理地址的转换,这里 DuVisor 是在 HU 模式下管理了二阶段页表的,而不需要进入内核态,这里的二阶段页表是一个 GPA 到 HPA 的映射。在转换后,还需要经过 RISC-V 的物理地址检查机制,如果要访问的物理地址处于 DuVisor 的管辖范围内,则执行这次访问,否则由内核生成一个错误,交给内核中的驱动程序处理。
其实能限制的还有很多,比如 Intel 的 PAMT,AMD 的 RMP 和 ARM 的 GPT 技术都可以做,所以感觉它所有的测试都应该是在 RISC-V 平台下跑的。
DV-Ext 在进行 I/O 和中断虚拟化的流程图如下图所示。
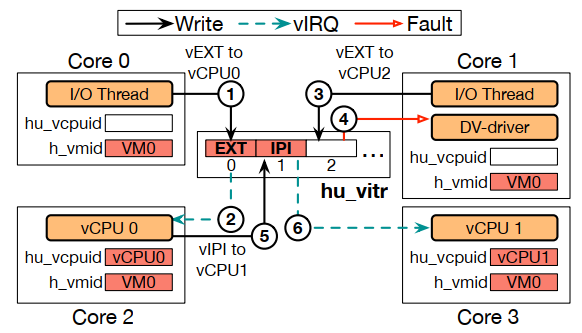
DuVisor 中的 I/O 虚拟化支持半虚拟化(如 virtio)和仿真(如 tty)。对于每个 PV 和仿真设备,DuVisor 都会在虚拟机初始化过程中生成专用的 I/O 线程。这些线程负责应答 VM 的 I/O 请求,并与主机的 I/O 设备交互。为了缩小攻击面,DuVisor 可以和内核绑定来绕过 virtio 后端,比如 vhost-user。
为了实现高效的半虚拟化 I/O 通知,DV-Ext 支持直接把 vEXT(虚拟外部中断)通过用户级 posted interrupt 注入到正在运行的 VM 中。posted interrupt 需要 hypervisor 进入内核态才能发,这意味着 vCPU 之间的通信和 HU 模式 helper 和它 VM 之间的通信必须经过主机内核,这与 DuVisor 的设计原则相悖。相反地,用户级 posted interrupt 就不需要内核参与。
这段主要强调的是用的是用户级 posted interrupt,不是(内核级?)posted interrupt。
具体来说,I/O 线程通过在 HU 模式下将中断向量写入 posted interrupt 寄存器中来注入一个 vEXT。如果目标 vCPU 在某个核心上运行,DV-Ext 会立即在那个核心上触发 vEXT。否则,DV-Ext 会记录这个 vEXT 信息,等到 vCPU 恢复运行之后再发送。
此外还有虚拟计时器中断,DV-Ext 支持直接触发一个到期的虚拟计时器。目前,DuVisor VM 可以不经过 VE 接收到一个计时器中断,但是目前设置计时器事件还是需要进入 VE,但是测试来看这对于 VM 性能的影响很小。
相对于预印本,这里补充了更多半虚拟化和计时器的事情,超级麻烦,真的超级麻烦,建议看原文。总之这一堆操作,除了计时器以外都不用进内核态,在用户态都能搞定,现在硬件扩展这么猛了吗。
文章进行了一些实验。首先是安全测试,那一个表里测了一堆 CVE,到了 DuVisor 全是 0,感觉跟日铁板一样,没啥可说的。
测试环境有些细节,因为 posted interrupt 可以极大改善中断敏感的场景,但是目前开源的 RISC-V 硬件不支持这个 feature,所以我们扩展了 DV-Ext 的中断虚拟化,让它支持到内核级别,并实现了一个优化的 KVM/QEMU(KVM-OPT)来支持内核级 posted interrupt。
这个其实是为了测试用,实际上跑还得是用户级 posted interrupt。
为了控制变量,我们稍微修改了一下 KVM(KVM-DVext)来保存和恢复和 DV-Ext 有关的虚拟化现场。并且实现了一个没有 PMP 检查的 DuVisor(DuVisor-noPMP)。
然后是精细的基准测试。在基准测试中将测试一系列操作,测试在 DuVisor 和 KVM 之间进行,测量一万次操作中两个虚拟机执行指令次数的平均值。测试结果如下图所示。

可以发现,DuVisor 在各类操作的执行指令数上均优于 KVM,和 KVM-OPT 一致。这证明 DuVisor 将 VM exit 等事件托管到用户态处理确实可以取得一定的优化效果。
下面是实际应用的测试结果。
研究中选取了一些真实环境软件进行了测试。使用 KVM-OPT 和 DuVisor 进行对比,结果如下图。

Y 轴是对比裸机的性能开销。
实际上还有一些细节,比如在 DuVisor 实现更好的网络驱动,使用 vhost-net 作为 KVM-OPT 的网络后端,测量之前充分预热消除了二阶段页表缺页的影响等等。
netperf 和 iperf3 结果相近,表示 KVM-OPT 和 DuVisor 都可以充分利用网卡带宽,性能开销相近,并且对比裸机没有产生更大的性能开销,说明简单实现的用户空间下的网络后端可以达到成熟的 vhost-net 的性能。
对于网络密集型应用 Memcached 的来说,DuVisor 和 KVM 的性能接近。然而,对比裸机,它们都产生了 35% 的虚拟化开销。性能降级的原因可能是更长的数据传输路径和次优的前后端通知。由于 I/O 虚拟化,到达 VM 之前大量的小 memcached 请求经过的路径比裸机上长。并且,由于后端驱动频繁 notify,客户 VM 的中断频率远高于裸机,导致 VM 中 memcached 线程处理请求的 CPU 时间短。我们同样在 Intel 和 ARM 平台上对比了 QEMU/KVM 和裸机上的 memcached 性能,同样发现有 15% 到 40% 的额外开销。
我觉得这个解释比预印本里的更好一些,也可能是架构更新导致的解释更明白了。
DuVisor 同样在 hackbench 上与 KVM-OPT 差不多。KVM 因为没用硬件中断虚拟化,所以产生了 12% 的开销。并且由于精细测试中图 d 的结果,也解释了 DuVisor 和 KVM-OPT 没有太大差异的原因,因为这个测试中有许多 IPI(处理器之间中断)。
在 CPUPrime 测试中,两者 VM 中执行均和裸机执行性能一样。
原来测试写的时候变成优化多少了,写反了,应该都是开销。而且对比下来,应该都是在 RISC-V 平台上做的测试,不是 x86 下的,所以感觉,确实没啥用。
同样,研究者还测量了 DV-Ext 对 KVM 执行的影响,测试以应用测试中 KVM 的性能为基准,测量 KVM-DVext 产生的额外开销,结果显示没有可辨影响。
这组对照实验做得很有道理,但是出现负 overhead 就很诡异。基本小于 +-5% 吧,也是可以接受的。
文章还测量了 PMP 对内存带宽的影响,结果显示毫无影响。
文章局限和结论
局限于:
- 嵌套虚拟化:没做,打算把 VE 直接给 L1 hypervisor 做
- 内存利用率:用了 PMP 导致内存利用率低,打算软件方法解决
- 支持 IOMMU:理论上可以支持
- DV-Ext 通用性:目前是在 RISC-V
上实现的,但是应用到其他架构上是可行的,因为它们共享相同的高级虚拟化函数
- 考虑 Intel VMX,都有对应的指令或者寄存器
- 主机内核漏洞:不关 DuVIsor 事
本文通过使用新的托管式虚拟化扩展来改造现有的硬件,提出了托管式虚拟化。在硬件扩展之上建立了一个用户级的管理程序,称为 DuVisor,它直接处理所有的虚拟机操作,而不需要在运行时切换进内核态。实验结果表明,DuVisor 的性能优于传统的管理程序。
个人评价
本文提出了一种全新的虚拟化方法,并且通过测试说明了在性能基本与 KVM 持平时具有更好的安全性。在 Network Algorithmics 一书中,作者提出了十五个优化网络系统的准则,其中一点是添加硬件改善性能,现在 FPGA 做计算加速的例子也很多,文章利用 FPGA 硬件加固虚拟化是一个十分新的尝试。DuVisor 的代码量在 30,000 行左右,并且开源了内核插件和其他测试脚本,可以说明工作是真实的。从行文来说,文章的实现是扎实的,测试也比较充分,成果可信度较高。
但是从实用性的角度,一个 DuVisor 只对应一个虚拟机,并且引入这种硬件必然增加成本。虽然在性能比 KVM 持平,安全性完全强于 KVM,但是其应用场景不足。虽然目标是赋能云厂商向租户提供当前虚拟化方案所难以保证的高可用性,但现实中已有的权衡尚且令人满意,可能在现实中并没有大规模使用的场景,设计目标应该针对的是要求高安全性的场景,如 VMM 等。当然,我认为这篇文章的尝试是值得肯定的,作为一项研究来说是比较完善的,在汇报的时候老师也在质疑实用性,我也持同样观点。不过 Intel 也在搞类似 RISC-V 的用户级虚拟化,这种模式今后或许也可以全部搬到 x86 平台下。
这么一看确实没啥用,真有用的时候再说吧,All it needs is time.