Bolt: Sub-RTT Congestion Control for Ultra-Low Latency 论文阅读
说起来 NSDI 刚开始就想着看看这个论文,大概都是上上学期的事情了,然后看了一点,之后就去干 SRv6 去了。过后很久导师把这个论文塞过来了,才想起来接着看。
这篇阅读里还会提到一些 Poseidon 的工作,但是那篇论文主要研究的是公平性。
主要是根据组会汇报 PPT 整理的,图片来自原论文。
观察
首先观察的是 DC 内网络流量的情况。作者提出高线速下 CC 应在突发负载下提供高质量的即时决策,并绘制了在 Google 内部 DC 中 RPC 数据包的分布函数,如下图所示。100Gbps 和 400Gbps 链路可以一次装载的 RPC 百分比用红线标出。
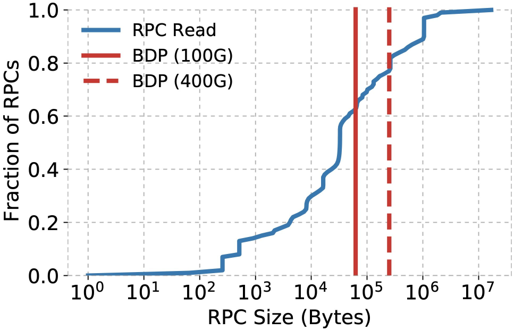
相当于求一个
的 。
实际上 DC 内的流量大部分是 RPC 流量,而 RPC 流量通常是 One shot Ping-Pong,也就是类似于一次 Ping,过了这次就没了。而 RPC 通常是突发性高,性能敏感的,文中提到中等大小的包不允许路由器过度积压,这就依赖于 CC 决策。而即使是一次错误或者慢 CC 决策,会导致几十毫秒的长尾(预测剩余带宽很大,实际很小)或利用率低(预测剩余带宽很小,实际很大),这样将导致网络降级。类似的负载还有分离式内存和机器学习负载,都是类似 RPC 这种的。
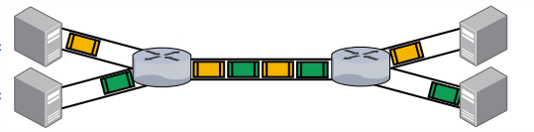
研究者做了一个实验,实验中拥塞通知在一个配置好的常数延迟后发送回发送方,以模拟基于 RTT 的反馈回路。他们使用 Swift CC 控制的两条流(拓扑如下图),第二条流在第一条达到稳定后加入,测量交换机上拥塞缓解的时间。实验还测量了通知在哪儿生成对反应时间的影响,Rcvr 是在接收方产生通知,Ing 是在交换机入口产生通知,Egr 是在交换机出口产生通知。
结果如下图。
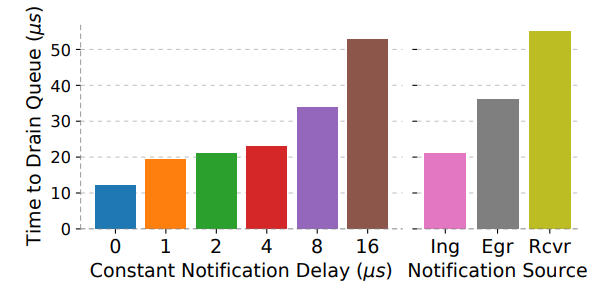
可以看出延迟呈非线性增加。这就说明低延迟反馈有助于更快缓解拥塞,因为反馈消息可能同样也被拥塞堵住了,这段时间内依然用原发送速率对网络发送,拥堵就更严重了。并且,在交换机入口处产生拥塞通知对于缓解拥塞有更大帮助。
然后研究者观察了低利用率反馈对网络利用率的影响。当一条流完成,但另一条流未完成时,未完成的流可以重新利用空出来带宽。传统的办法是等待 RTT 变化,按 CC 扩大 cwnd,但这样无法充分利用,因为要等至少一个 RTT 才知道可以扩大 cwnd。现在已有的改进是在稳态下维护一个等待队列,等到有空闲就用这个队列补充腾空的带宽,比如 HPCC 设置利用率为 150% 以超售带宽,把一半的 BDP 放在等待队列。但要恢复到单流占满,Swift 需要 25 个 RTT 的。如下图所示。
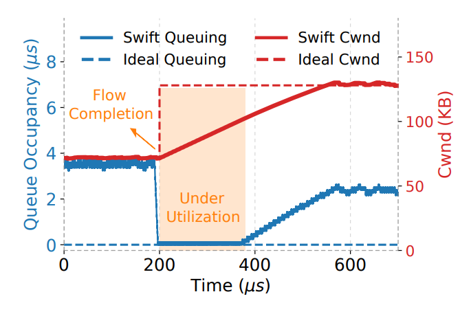
理想中,其余流应当立刻知道已完成流的 cwnd,然后直接利用腾空的带宽。
以上总结为两个关键点:
- 细粒度的 CC 算法:需要知道在哪儿拥塞,拥塞多少;拥塞时和低利用时正确地 ramp down/up,并且需要在网遥测,测量队列占用和链路利用率
- 最小化控制延迟:减小拥塞通知延迟和低利用率反馈延迟
设计
针对以上问题,Bolt 提出了三个设计
亚 RTT 控制(Sub-RTT Control,SRC)
使用亚 RTT 控制将拥塞通知延迟降到理论最低。下图就展示了基于 ACK 的反馈和基于 SRC 的反馈的区别。
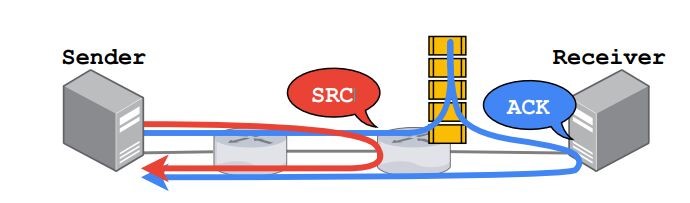
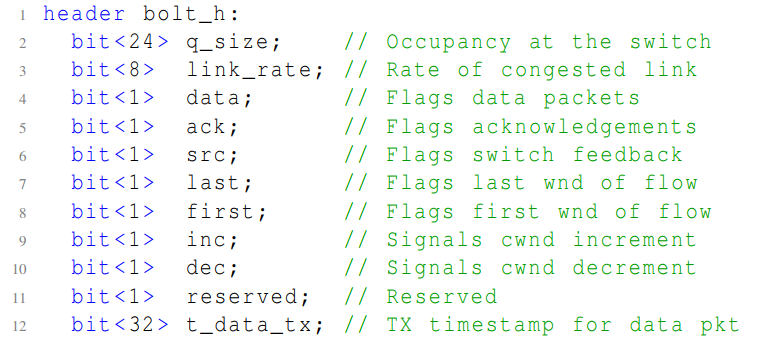
在传输中,优先传输 ACK 和 SRC 包。SRC 对传输层头部添加了如下 9 字节信息。
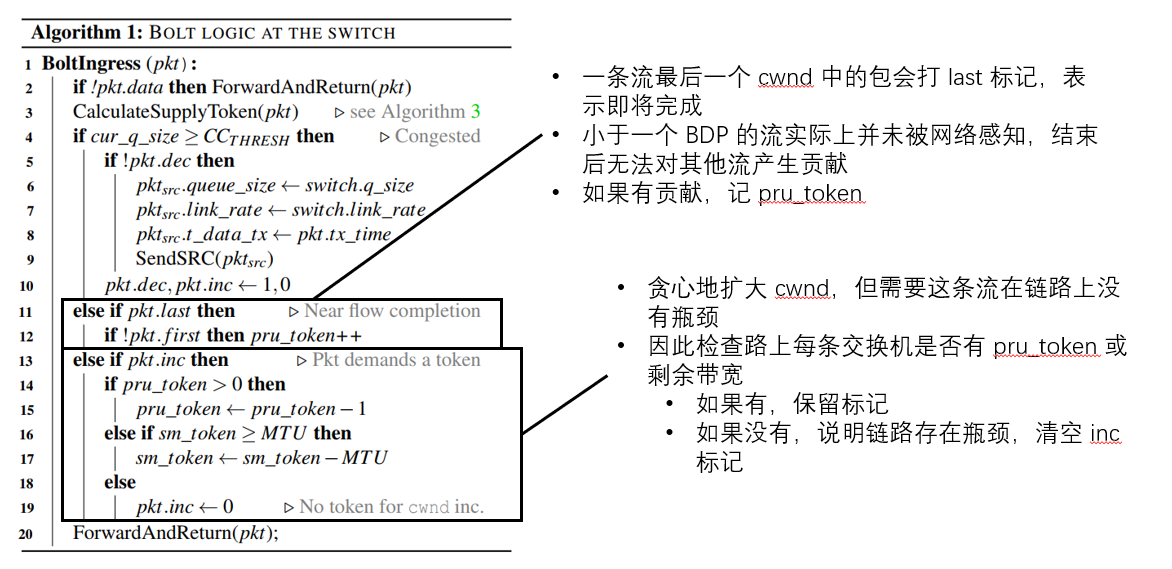
在路由器端的逻辑如下图。

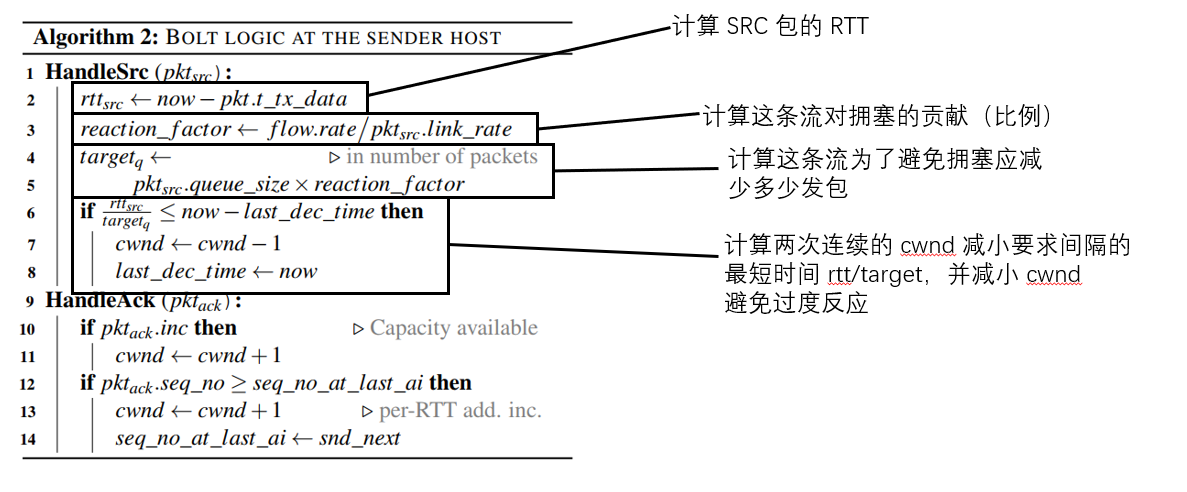
在主机端的逻辑如下图。
主动提升(Proactive Ramp Up,PRU)
使用主动提升来掩盖可预见的低利用率反馈延迟。
在路由器端的逻辑如下图。
在主机端的逻辑如下图。

供应匹配(Supply Matching,SM)
使用供应匹配从不可避免的低利用率事件中快速恢复,比如流移出链路的情景,这时 pru_token 失效,需要重新计算链路可提供的传输能力(字节数)。
在路由器端的逻辑如下图,其实就是算 supply token 那个函数。

在主机端的逻辑如下图。

实现和测试
是在 P4 交换机上实现的,感觉也不用说了,这种东西肯定要可编程交换机。
测试结果表明也是十分地有效,看原论文吧没啥好说的。有一点是因为 Bolt 使用亚 RTT 控制,因此比理想状态下基于 RTT 控制的反应更快,所以启动得是比理想状态快的。
然后和 HPCC 和 Swift 的对比其实有点拉偏架,HPCC 目标优化的是 RDMA 场景,有利于短流量,Swift 目标优化的是高 IOPS 场景,存储型负载,并且 Swift 没有在网遥测,感觉场景没拉齐,不是很好说它到底好不好,或者哪里好。只能说是针对 Swift 的升级版,很多突发状况,比如丢包什么的,就会直接降成 Swift。
评价
看了全局流控 or 端到端拥塞控制,说实话没太看懂。Bolt 是借助在网遥测来实现全局流控,当然在网遥测可以解决一堆事情,比如 Poseidon 解决的公平性问题,毕竟 DC 内网络结构是确定的,不像广域网那么混乱,或者说测不出来,使用一定的中心化方法是理论可行的。网络可以自行决定怎么给主机分配带宽,而不是主机自己去黑盒里摸带宽出来,但是这个广域网上做不了,别想了。