Host Congestion Control 论文阅读
文章图片均来自原论文。
Abstract
系统和网络界的传统观点认为,拥塞主要发生在网络内部(fabric congestion)。然而,高带宽接入链路的采用和主机内资源相对停滞的技术趋势,导致了主机拥塞的出现,即,使网卡和 CPU/内存之间的数据交换成为可能的主机网络内的拥塞。这种主机拥塞改变了数十年拥塞控制研究和实践中根深蒂固的许多假设。
这里的 fabric congestion 应该是 Swift 里说的那个,但是 Swift 说的 endpoint congestion 应该就是这篇文章的 host congestion。
我们提出的 hostCC 是一种同时处理主机和网络结构拥塞的拥塞控制架构。首先,除了源于网络内部的拥塞信号外,hostCC 还收集主机拥塞信号,以捕捉主机拥塞的精确时间、位置和原因。其次,hostCC 引入了亚 RTT 粒度的主机本地拥塞响应,利用拥塞信号在网络流量和主机本地流量之间分配主机资源。最后,hostCC 同时使用主机和网络拥塞信号,以 RTT 为粒度分配网络资源。
我们在 Linux 网络协议栈中实现了 hostCC。我们的 hostCC 实现无需修改应用程序、主机硬件和网络硬件;此外,它还可与现有拥塞控制协议集成,以处理主机和网络结构拥塞问题。对有无 hostCC 的 Linux DCTCP 的评估表明,在主机拥塞的情况下,hostCC 能显著减少主机的排队和数据包丢弃,从而提高网络应用程序的吞吐量和尾部延迟性能。
但是那个代码格式真的不行,tab 空格混用,缩进一坨,并且实验代码还没传,我不好说。
Introduction
说白了就是早年的网络拥塞控制认为丢包点靠近拥塞,主机资源无限,现在这俩假设都不成立了。因为网络设备在发展,主机资源,比如 CPU 速度、缓存大小、访存延迟、每核内存带宽、网卡缓冲区大小等,发展跟不上网络,所以导致了主机网络开始拥塞。但是主机网络是无损的,也就是除非网卡拥塞了,否则不会因为包损坏丢包,那么就出现了一个问题,我们现在默认出现丢包都是网络内部丢包,但是事实上是,主机拥塞了,网卡直接把包丢了,但网络内部可能是正常的,也可能是出现拥塞的,所以论文中说主机拥塞会导致排队并在远离实际的拥塞点的地方丢包。
第二点,在做拥塞控制的时候,大家都假设竞争的流存在拥塞控制,也就是出现拥塞了会回退,而不是接着发包让网络变得更拥塞。但是主机网络内部来自「网络外部」的流量(比如生成 CPU 到内存流量的应用)没有拥塞控制机制,它可能在亚 RTT 粒度里显著变化,这就需要我们重新思考拥塞控制。
Host Congestion
Background: the host network
文中将主机网络的物理架构拆成了两部分:从网卡到集成 IO 控制器(IIO),这两端都是 PCIe 连接,然后是从 IIO 到内存。
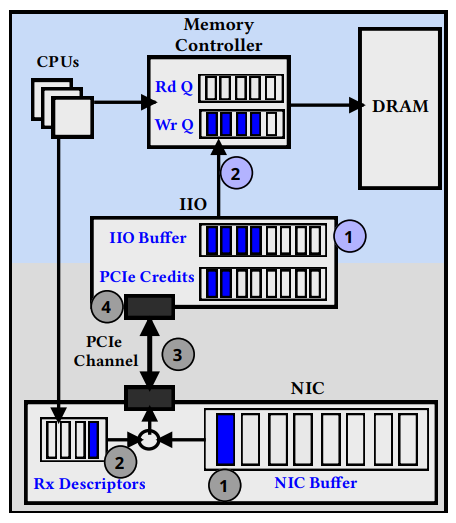
首先是网卡到 IIO 的部分,分四个阶段:
- 当一个包到达时,网卡将数据包排队放入其输入缓冲区(通常是一个小 SRAM 中)
- 接下来,网卡获取一个描述符,描述符为网卡提供一个主机内存地址,以便直接把包 DMA 到内存,网卡驱动定期补充这些描述符
- 重要的是,PCIe 是一种使用基于 credit 的流量控制机制的无损连接,它是通过固定数量的(硬件特定的)credit 实现的。当 credit 可用时,网卡会实例化 PCIe 上的 DMA 请求(使用 PCIe 事务执行);DMA 一个数据包可能需要多个 PCIe credit。PCIe 是一种无损连接,一旦 DMA 启动,数据包就可以安全地从网卡缓冲区中移出。如果 PCIe credit 耗尽(我们将在下面讨论潜在的原因),则在 credit 补充之前无法启动 DMA。
- IIO 捕获每个 PCIe 事务并启动对内存的写入(下面讨论);重要的是,PCIe credit 是只有当 IIO 成功向内存发出写操作时才会补充。
credit-based 不知道怎么翻译的,但是感觉和虚电路上的 credit 没什么两样。
IIO 到内存的数据路径。现代主机支持直接缓存访问(例如,使用 DDIO),允许网卡将数据包直接 DMA 到最后一级缓存(LLC)。精确的 IIO 到内存的数据路径取决于是否启用或禁用 DDIO。我们首先描述禁用 DDIO 的数据路径;然后讨论启用 DDIO 的情况。
这里的 LLC 指的是 CPU 的 L3,也就是 DDIO 直接把数据包从网卡运到 L3,经过 CPU 处理之后再写到内存里,如果 DDIO 关闭,就是 IIO 把包先送到内存,然后 CPU 从内存取包加工后再返回内存。
- 当 IIO 接收到 PCIe 事务时,将请求排队到 IIO 缓冲区中。
- IIO 从它的缓冲区向内存控制器缓冲区发出请求,由控制器执行对 DRAM 的最后写入。重要的是,IIO 到内存控制器的数据路径也使用基于 credit 的流量控制机制的无损连接;IIO 只有在内存控制器的写队列未满时才可以向内存发出写请求。如果这个写队列已满(例如,由于 CPU 的其他内存请求),则请求仍然在 IIO 缓冲区中排队。一旦写队列空闲,IIO 就将请求传输到内存控制器写队列;这就需要一个内存写带宽大小的 cacheline 的代价。由于 IIO 到内存控制器的数据路径是无损的,因此一旦请求被允许进入内存控制器写队列,就可以安全地从 IIO 缓冲区中移出请求。在这一点上,IIO 也如上所述地补充 PCIe credit。
如果启用了 DDIO,IIO 直接将 cacheline 传输到 LLC。这可能需要将已经存在的 cacheline 驱逐到内存控制器。
但是 DDIO 官方文档说 DDIO 读操作不会引起 Cache 驱逐,不知道咋回事。可以参考下面的实验,可能是一些占用内存的 App 会把网络包从 Cache 里驱逐出去的意思。
因此,如果 DDIO 被启用并且不导致驱逐,它减少了 IIO 写请求的延迟,因为从 IIO 到 LLC 的光速延迟比从 IIO 到 DRAM 的要小。然而,如果它导致了 Cache 驱逐,我们就回到了禁用 DDIO 的情况:每次驱逐不仅会导致需要一个内存写带宽大小的 cacheline,而且还会导致更高的延迟,因为 IIO 到 LLC 的写只能在驱逐完成后执行。
当内存控制器写队列满时,由于 IIO 到内存请求延迟的膨胀,我们观察到多米诺骨牌效应:随着 IIO 到内存延迟的增加,更多的请求在 IIO 缓冲区排队,PCIe credit 补充会引起更大的延迟,PCIe 可能会耗尽 credit。因此,PCIe 带宽仍然未得到充分利用,导致数据包排队并最终在网卡缓冲区中被丢掉。
他想说的是 IIO 到内存的链路时延会反压到网卡上导致丢包。
Understanding impact of host congestion
使用了三个程序,可能是自己写的:
- NetApp-T:它生成四条长流,每个流从一个发送端 CPU 核心到一个接收端 CPU 核心,跑在 NIC-local NUMA 节点上(DCTCP 需要至少四个核心才能在不拥塞的情况下饱和 100Gbps 的网卡);
- NetApp-L:在 NIC-local NUMA 节点上的发送端和接收端 CPU 核之间生成延迟敏感 RPC(大小从 128B 到 32KB 不等)
- MApp:产生具有 1:1 读写比和连续存储器访问模式的 CPU 到内存流量
他那个 NIC-local NUMA node 是真不知道啥意思,应该是网卡和 CPU 是在一个 NUMA 节点上的吧。
通过增加 MApp CPU 核心的数量,我们将 MApp 给内存互连的负载从 1 倍增加到 3 倍,从而增加了运行中的内存请求的数量(在没有任何其他内存流量来源的情况下,使用 1 倍到 3 倍的 MApp 核心导致观察到的总内存带宽分别为 16.0GBps、28.7GBps 和 34.8GBps),然后使用标准的测试程序进行测试。结果显示,即使启用了 DDIO,主机拥塞也会导致网络吞吐量降级(>35%),下图显示了在使用和不使用 DDIO 的情况下,吞吐量、丢包和内存带宽利用率随着主机拥塞程度的增加而增加的情况。
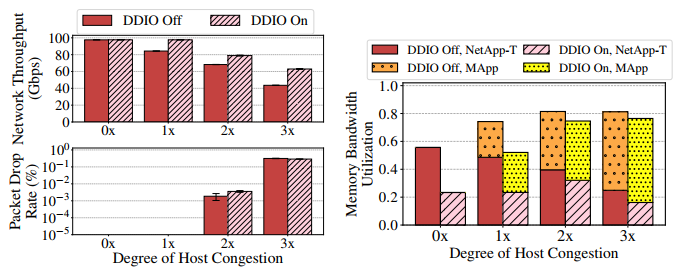
可以看出 DDIO 稍有帮助,但不多。当出现主机拥塞的时候,可以看出 MApp 会挤压 NetApp-T 的带宽利用。0× 的情况很简单:没有主机拥塞,因此网络流量能够饱和接入链路带宽。启用 DDIO 降低了内存带宽的利用率,因为 CPU 能够在数据被驱逐之前使用它;然而,内存带宽利用率是非零的,因为缓存污染确实会发生,因为 LLC 是在所有内核之间共享的,所以不能保证完美的缓存命中率。当 1× 且禁用 DDIO 时,内存带宽利用率接近饱和;因此,内存访问延迟(以及每次内存访问的 CPU 周期数)开始增加。因此,网络吞吐量被计算限制(更准确地说,被接收端缓冲区限制),无法使得接入链路带宽饱和。DDIO 在这样的场景中表现出色:较低的内存带宽利用率使得内存访问延迟较低,每次内存访问只需要使用较少的 CPU 周期,从而允许使用 DDIO 的网络流量继续使访问链路带宽饱和。2× 和 3× 的情况就是上文所说的多米诺效应。
并且随着 MApp 核心数量的增加,分配给网络流量的内存带宽比例越来越小。实验表明内存带宽分配基本上与单个实体(IIO 或 CPU)产生的负载成正比;这意味着,随着 MApp 核心的增加,MApp 产生越来越大的负载,但 IIO 发出的最大请求数保持不变(取决于 PCIe credit 限制)。因此,CPU 能够快速获取更大比例的内存带宽,从而为网络流量创造更多的主机竞争。
实验又研究了 MTU 大小和流数量对主机拥塞的影响,是在 3× 主机拥塞的情况下做的,结果如下图。
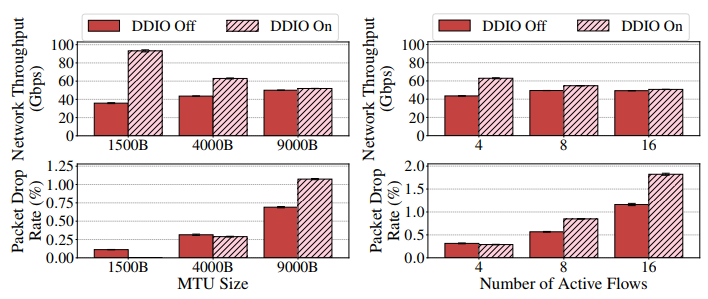
实验表明这时候大 MTU 和多流场景下,启用 DDIO 没用,原因是缓存驱逐导致的。
实验还研究了时延敏感的 RPC 在主机拥塞下的尾延迟情况,如下图所示。
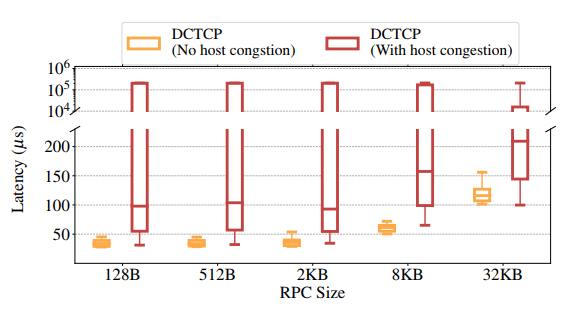
结果表明可能导致数个数量级的尾延迟增加。实验中让三个应用一起跑,主机拥塞是 3×。NetApp-T 和 MApp 的表现仍然保持稳定,主要因为 NetApp-L 引入的流量不大。NetApp-L 尾延迟增加是由于如下三个原因:
- 网卡缓冲区的排队延迟
- 由于网卡缓冲区丢包而导致的重传和超时延迟
- 由于主机拥塞导致内存访问中的 CPU 周期增加而导致的更大的 CPU 处理延迟
基于之前的观察(接近 0.3% 的丢包率),P99 延迟由 1. 和 3. 主导,P99.9 由 2. 主导——对于启用和禁用 DDIO(观察到相似的下降率),P99 延迟增长大约是 60-100μs,这接近网卡缓冲区的最坏情况排队延迟;P99.9 延迟增长接近 200ms,这是默认的 Linux 最小重传超时(RTO)值。较小的 RPC 遭受更高的尾部延迟增加,因为任何数据包丢弃都需要等到超时;对于较大的 RPC,当有多个流入的数据包时,Linux Tail Loss Probe(TLP)机制是有效的(具有较小的超时)。隔离网卡缓冲区并不能解决这个问题:较小的网卡缓冲区大小将导致更大数量的丢包,增加 2.;另一方面,较大的网卡缓冲区大小将增加 1.。
这些实验分析挺有道理的,MApp 可能是为了模拟大量内存读写占用,比如同时跑 KV 数据库啥的。
hostCC
Host congestion signals
记:
为网卡的接受速率 为 PCIe 可以维护的最大入字节数(一个固定的硬件相关常数,取决于最大信用点数和 PCIe 事务层包大小) 为网卡到 IIO 之间的延迟(取决于硬件) 为 IIO 到内存之间的延迟
正如 Introduction 中所讨论的,
把花体都打成正体了,啥都打花体真的烦。
综上,
在没有主机拥塞的情况下,有
文章使用 IIO 占用量作为主机拥塞信号。首先,IIO
占用量提供了关于主机拥塞的时间、位置和原因的准确信息:IIO
占用在内存控制器拥塞时立即增加(时间和位置的准确性),并且只有在内存控制器拥塞时才增加(原因的准确性)。其次,IIO
占用量可以与另一个统计数据——IIO 插入率(定义为 PCIe 将数据插入 IIO
缓冲区的速率)相结合,以测量各种其他有用的指标;例如,瞬时 PCIe
吞吐量(网卡缓冲区消耗的速率)等于瞬时 IIO 插入速率乘以 cacheline
大小,主机延迟
Host-local congestion response at sub-RTT granularity
经典拥塞控制协议的一个概念解释是,为了处理网络内部的拥塞,这些协议(以及网络交换机)在拥塞点竞争的实体之间分配网络资源。hostCC 架构中的第二个关键技术思想是由这个概念观点驱动的:为了处理主机和网络拥塞,hostCC 在拥塞点竞争的实体之间分配主机和网络资源。为了实现这一点,hostCC 在发送方和接收方主机上引入了主机本地拥塞响应,该响应使用前一小节中讨论的主机拥塞信号,跨网络流量和主机本地流量分配主机资源。
资源分配取决于底层的策略;hostCC架构并没有规定精确的资源分配策略——就像不同的网络资源分配机制使用不同的网络分配策略(最大最小公平,加权最大最小公平,优先级等)一样,我们设想
hostCC
包含各种主机资源分配策略和各自的实现。对于下面的讨论,我们假设策略周期性地计算目标网络带宽,记为
鉴于上述情况,hostCC 的主机-本地拥塞响应机制使用四种可能的操作机制来描述,如下图所示分别描述。
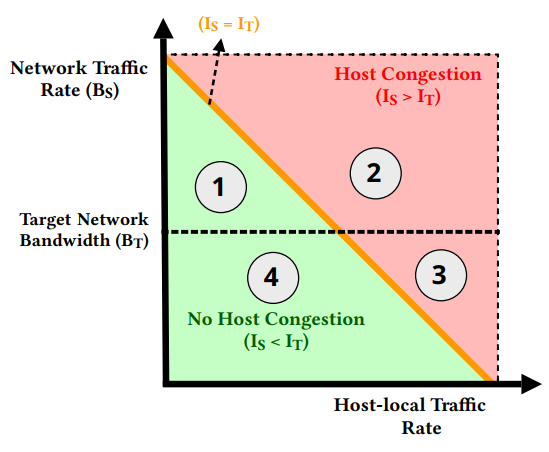
无主机拥塞,网络流量已满足目标网络带宽
这部分是图中的①部分,在这种情况下,主机不拥塞(
这部分是比较理想的情况,主机内部有资源,并且主机不拥塞,那就用 AIMD 调目标速率,然后让网络把主机资源带起来就好了。毕竟目标是 hit 到那条线的。有点像公平性的那个图。
主机拥塞,网络流量已满足目标网络带宽
这部分是图中的②部分,在这种情况下,主机拥塞,网络流量使用的资源超过了满足目标带宽所需的资源。因此,在这种情况下,正确的操作是减少分配给网络流量的资源,而不减少分配给主机本地流量的资源。为了实现这一点,hostCC 再次依赖于网络拥塞控制协议中使用的 AIMD 风格机制:它将主机拥塞信号反映到网络拥塞控制协议中,从而降低网络流量速率。
这部分是
,但是 ,也就是 PCIe 总线速率满足网络带宽,但是 IIO 占用已经到阈值了,感觉应该是 AIMD 调高了的瞬间。总之这时候相当于主机忙不过来,那就让网络慢一点。
主机拥塞,网络流量未满足目标网络带宽
这部分是图中的③部分,在这种情况下,主机拥塞,但分配给网络流量的资源比满足目标带宽所需的资源要少。既然存在主机拥塞,就必须减少分配的资源;由于网络流量没有满足目标带宽,hostCC
首先减少分配给本地流量的资源(这发生在亚 RTT
粒度上)。然而,这还不足以避免网卡缓冲区的累积和丢包。要了解原因,需回忆
PCIe 带宽利用率
这里的情况应该是有 MApp 这种 IIO 被内部应用占用而不是网络占用的情况,这种时候的策略是先把资源分给内部占用,调低网络带宽。总之那也 kill 不了,只能等,所以调低带宽,减少资源使用,避免进一步拥塞。
无主机拥塞,网络流量未满足目标网络带宽
这部分是图中的④部分,在这种情况下,主机没有拥塞,网络流量拥有的资源少于满足目标带宽所需的资源。因此,主机拥塞响应为网络流量分配更多的资源;这种分配又是隐式的,因为它再次依赖于 AIMD 风格的机制——由于主机没有拥塞,网络流量不会在主机上被标记拥塞信号,从而允许网络流量增加其速率并获得未使用的主机资源(如果网络内部没有拥塞)。隐式增加分配给网络流量资源可能需要多个 RTT,甚至可能不可行(例如,由于网络拥塞);尽管如此,主机拥塞响应做出保留决策,在此情况下不增加分配给本地流量的资源,以避免在达到目标网络带宽之前出现主机拥塞。
这种情况还是 AIMD 调,属于网络起步阶段,主机有资源,并且网络流量还没到目标,那就加速起步就好了。
Network resource allocation at RTT granularity
考虑主机拥塞(
假设网络流量以速率
Implementation
总之 Intel CPU 里有 MSR
可以获取 IIO 累积占用量,再通过 TSC
获取纳秒级时间戳。研究中采用的是一段时间内的平均 IIO
占用量,因为这个累积占用量是以一定频率更新的。只能说他给的式子用量纲分析确实是对的,但是没明白有啥意义。测量
Evaluation
Figure 18 很有意思。
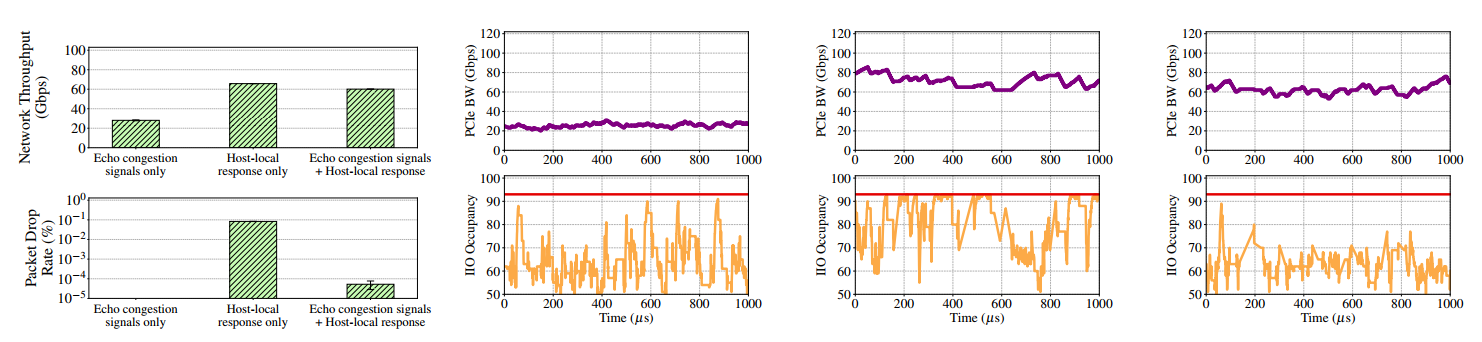
这里可以看出,只反映网络拥塞信号,吞吐量很低,但是只反映主机拥塞信号,吞吐量和两个都反映差不多了。这里我认为和谁该来负责拥塞控制的观点类似,考虑 CSMA/CD,主机发拥塞信号 Host 公平了,但是 IIO 和网络内部就开堵,丢包率往上涨,加上网络拥塞信号的话,丢包率就下来了,但是丢包率下降并未导致其网络吞吐进一步提升,反而有些下降,毕竟是二重限制。所以可能确实主机上是主要影响,用 CSMA/CD 风格的 CC 会好一些。
Comment
感觉还是要分析端设备的拥塞,原来粗粒度的分析已经没啥增长点了,只能钻进主机里接着讨论网卡到内存的细粒度路径,还是有点东西的。看起来 CPU 也支持这么分析,以后确实可以借鉴一下。
ECN 限时返场,但是挺有用的,难蚌。